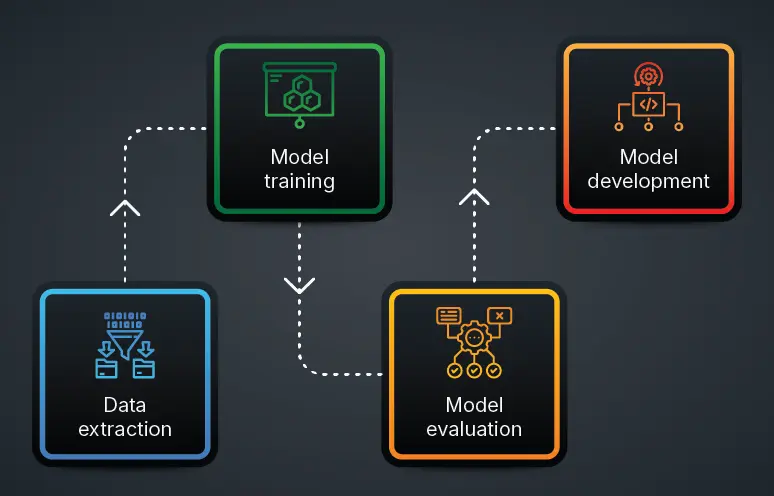
Machine learning is becoming a core part of how modern businesses operate, but getting real value from it takes more than just building a model. That’s where we require a machine learning pipeline. Machine learning pipeline is a step-by-step process that connects everything, from collecting data to deploying a model into one smooth flow.
A well-designed ML pipeline saves time, reduces errors, and helps you scale with confidence. It also brings more structure to your projects, so teams can focus on what really matters, solving problems. ML pipelines have become essential with growing demand for real-time insights.
Working with a machine learning services provider is essential, especially when understanding the pipeline, which lays the groundwork for successful AI adoption and implementation.
In this guide, we’ll explore what is a machine learning pipeline, why it matters, what are its components and use cases, and what are the best practices to follow while constructing an ML pipeline.
What is a machine learning pipeline?
A machine learning pipeline is a systematic automated workflow that streamlines the process of developing, training, testing, and releasing ML models. It combines every phase of the ML lifecycle, from data gathering to model monitoring into one continuous, reproducible process.
It comprises a series of computational processes that transform raw data to a deployable machine learning model. These include data collection, preprocessing, feature engineering, model training, and evaluation. By structuring these tasks in the pipeline form, developers can manage the production and maintenance of data science projects.
Pipelines are needed in big-scale machine learning project management. They ensure that processes are executed constantly. They provide a modular setup that allows reusability of the components and facilitate easy updates and improvements. Pipelines also assist in minimizing errors by integrating validation and logging mechanisms at each step. The modularity allows it to be seamlessly integrated into other systems, which increases collaboration among teams. This reduces the complexities in managing large-scale machine learning projects.
6 components of a machine learning pipeline
For a better understanding of machine learning pipeline, it’s important to break it down into its fundamental building blocks. These components play a specific role in keeping the ML pipeline architecture efficient, repeatable, and scalable.
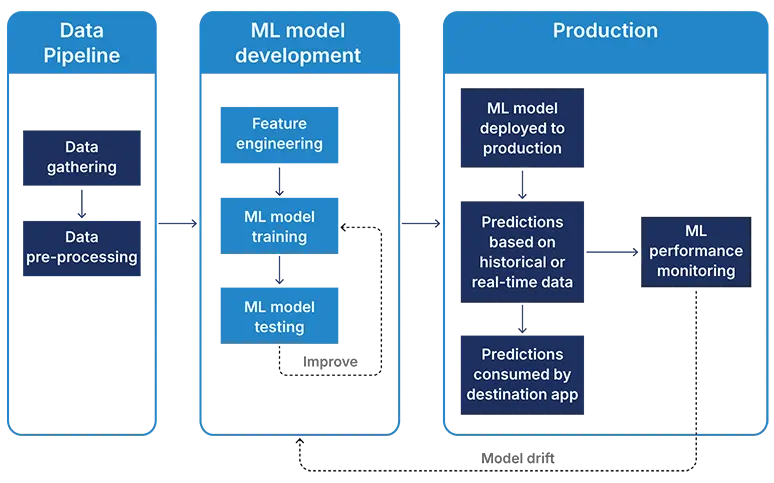
1. Ingestion and data collection
Data ingestion and collection processes bring raw data from different sources and prepare it for processing. This process includes establishing a connection to databases, APIs, or even scraping data from web sources. Ingestion converts data into a standardized format to make it compatible with downstream processes. This task can be automated, so new data can be fed into the pipeline continuously with minimum human intervention.
Handling this data flow is important because data quality and consistency affect all the following steps in the pipeline. Effective data ingestion techniques provide for data validation, cleaning, and preliminary exploratory analysis that assist in detecting anomalies earlier. This phase lays the groundwork for creating machine learning models because any misalignment here can propagate through the pipeline, impacting model accuracy.
2. Data transformation and preprocessing
Transformation and preprocessing of data involve cleaning and structuring raw data to prepare it for training models. In this process, missing data is managed, duplicate data is removed, and categorical variables are transformed into appropriate numerical formats. Scaling and normalization procedures are also typical to maintain data consistency. This improves the quality of data, directly impacting model results.
Transformation requires domain expertise to establish that the alterations correlate with real-world implications. Pipelines apply these repetitive operations automatically, guaranteeing they are carried out uniformly throughout data sets. Automation ensures standard preprocessing strategy across projects, lowering the possibilities of human error. Accurately pre-processed information leads to quicker training and more accurate models.
3. Feature engineering
Feature engineering is the process of choosing, modifying, or generating features from raw data which will improve a model’s predictive ability. This phase can have a major impact on a model’s capacity to derive insights from data. Feature selection is a process of selecting the most relevant attributes, whereas transformation may involve applying domain knowledge to come up with new features which reflect patterns within the data.
Effective feature engineering requires a deep knowledge of the data and its surroundings. Pipelines enable one to try various sets of features and enable automated testing for determining the most effective features. Such flexibility is essential for the continuous enhancement of models. Automated feature engineering software can help speed it up and help data scientists concentrate on interpreting results.
4. Model training
Model training is the process of teaching a machine learning model to learn hidden patterns using cleaned data. It requires selecting appropriate algorithms with the ability to generalize on unseen data. The training process includes the adjustment of model parameters to reduce prediction errors, iterating to improve model performance. This is a computationally rigorous process that requires optimal utilization of computational resources.
Pipelines make it possible to integrate different tools and frameworks to enable training. This helps to track multiple models and hyperparameters and apply methods such as k-fold cross-validation to build robust models. Training automation in pipelines accelerates the experimentation process to enable quick iteration and comparing different solutions to determine the best model for a given task.
5. Model evaluation
Model evaluation employs validation data to estimate the performance of the model following training. Accuracy, precision, recall, and F1-score are some of the most widely applied measures for determining how effectively the model has learned patterns from training data. Evaluation assists in detecting overfitting or underfitting problems, leading to additional tuning or re-evaluation of the model and its parameters.
A process of evaluation within a pipeline guarantees uniform standards for model performance measurement. Pipeline tools automatically produce reports, which make it simple to compare models. Standardizing measures of evaluation allows pipelines to provide an objective system of choosing the best model, ensuring the gains in performance are measurable and defendable in production.
6. Model deployment
Model deployment is the implementation of a machine learning model into an actual environment where it can make predictions against fresh data. This process transforms the trained model into a form suitable for production, where it is incorporated into larger systems or APIs to make it accessible. Deployment must factor in scalability so that the model is able to support fluctuating volumes and still be operational.
Pipelines streamline the deployment process with smooth handovers from development to production. They employ monitoring and logging to alert teams for problems in real time. And minimize the risk of errors by standardizing deployment processes and ensure that models continue to function. Automated rollbacks enable rapid returns to prior states if new deployments are faulty.
Why is ML pipelining important?
ML pipelines disintegrate the machine-learning process into autonomous, reusable units. These units of work can be pipelined together efficiently, allowing not only model development simplification and speedup but also the guarantee of redundant work elimination. This modularity permits various processes to integrate seamlessly, creating a space where experimentation and optimization can happen without starting the workflow from scratch.
In addition, ML pipelines are central to machine learning system productionization. They help in process standardization, error reduction, and guarantee models are accurate and scalable. Pipelines allow data scientists and data engineers to manage the complexity involved in the end-to-end machine learning process through workflow automation. This helps in the creation of strong, dependable solutions for a wide range of applications, such that models behave consistently at deployment time.
What are the advantages of ML pipelines?
When implemented correctly, a pipeline in machine learning simplifies everything from experimentation to deployment. Here’s why teams are shifting from manual processes to streamlined, automated AI pipeline setups.
-
Reproducibility
ML pipelines help make sure a model always gives the same results when it uses the same inputs. This is important because it lets teams easily compare new models with older ones and avoid wasting resources. When experiments follow a set structure, reproducibility keeps results consistent and allows automatic adjustments to the model, helping it perform well over time and making the testing process more reliable.
-
Efficiency
ML pipelines automate routine tasks, be it data preprocessing, model testing, or feature engineering, to save time and minimize the risk of errors, hence improving overall productivity. This optimized process not only speeds up development cycles but also delivers a more consistent and error-free implementation of intricate machine learning pipelines.
-
Scalability
ML pipelines are scalable, with the ability to accommodate growing amounts of data and compute complexity without excessive rework. This flexibility enables the easy incorporation of new data sources and algorithms and allows systems to scale up with altering project needs and technology developments.
-
Ease of deployment
ML pipelines simplify deploying models into production by streamlining the shift from development to run-time environments. Incorporation into applications or systems is simplified through a well-defined pipeline for model training and testing, enabling fast and effective model deployment. This reduces the time to market for new products and enables continuous model delivery, thus increasing business capability to respond to changing demands and opportunities.
-
Collaboration
ML pipelines also foster collaboration among data science and engineering teams through a documented, structured workflow. This setup makes it easier to understand team members’ contributions and streamlines coordination. When making modifications such as adding new data sources, adjusting model parameters, revising feature engineering steps, or combining new models, pipelines define the effect clearly.
This ensures all team members remain informed and in sync. Such clarity in the process makes for more streamlined and unified development, less prone to errors or miscommunication and accelerating the introduction of better models into production.
What are the use cases of a machine learning pipeline?
The true value of a machine learning pipeline is revealed when it’s applied to solve real business problems. ML pipelines help turn data into decisions faster and more reliably.
-
Customer churn prediction
Automatically collect user activity data, clean it, and pass it on to a predictive model to mark customers at risk.
-
Fraud detection
Consume real-time transaction data, transform it in real time, and use anomaly detection models to highlight suspicious behavior.
-
Recommendation engines
Continuously analyze product or content suggestions based on user choice, behavior, and context signals.
-
Predictive maintenance
Utilize IoT and sensor data to forecast equipment failures before they occur, minimizing downtime and repair costs.
-
Marketing attribution
Combine several sources of data to train models to correctly allocate credit along customer touchpoints.
What are the challenges and considerations in ML pipelines
Every well-designed machine learning pipeline architecture faces technical and operational obstacles. Understanding these challenges early can help you plan better, reduce risks, and avoid bottlenecks.
1. Data quality
The most common challenge is inaccurate, inconsistent, or incomplete data. It can make a negative impact on model performance and reliability.
You can apply strong data cleansing and validation procedures to ensure data quality. Additionally, you can use data normalization, missing value imputation, and outlier detection.
2. Feature engineering complexity
Choosing and engineering meaningful features from raw data can be difficult, particularly for complex data sets.
Use domain knowledge and exploratory data analysis to determine meaningful features. Try different feature transformation methods, including dimensionality reduction, polynomial features, or embedding representations. Use automated feature selection techniques and feature importance analysis as well to make the feature engineering process simpler.
3. Model selection and tuning
The challenge is to select the right ML algorithm and tune its hyperparameters for a specific problem. It can be time-consuming because it is computationally intensive.
To resolve this challenge, you can consider streamlining the process. Run an experiment of a range of algorithms and hyperparameter configurations. It will help you identify the optimal-performing model.
And to make it an effective process, you can use methods like cross-validation, grid search, and Bayesian optimization. It will guide your search across the hyperparameter space.
And lastly, you can use automated machine learning tools to simplify experiments and help find high-performing configurations with minimal manual intervention.
4. Data privacy and security
The challenge is to maintain data privacy and security all the while managing sensitive information. It could be PII (Personally Identifiable Information).
With such concerns, you can apply data anonymization methods like data masking. And then, comply with data governance and compliance regulations (e.g., GDPR, HIPAA) while processing personal data.
5. Model interpretability and explainability
Comprehending and rendering the decisions of ML models, especially in high-risk or regulated environments, are challenging tasks.
Use interpretable ML models like decision trees, linear models, or rule-based models that have clear explanations of model predictions. Apply post-hoc interpretability techniques like feature importance analysis, SHAP values, or LIME (Local Interpretable Model-agnostic Explanations) to explain complex models. Also, write down model assumptions, constraints, and doubts to help stakeholders grasp and trust them.
6. Deployment and scalability of models
Deploying ML models to production and making them scalable, reliable, and maintainable often presents significant challenges.
Containerize ML models with Docker and Kubernetes to enable deployment on various environments and scaling features. Adopt microservices architecture to isolate components and scale services independently. Leverage cloud-based infrastructure and serverless platforms for elastic scalability and resource efficiency. Have strong monitoring and logging practices to monitor model performance, resource usage, and issues in production.
5 best practices to follow while constructing an ML pipeline
Even the most advanced ML pipeline can fall short without the right development and deployment practices. Whether you’re scaling or just getting started, certain principles help ensure your machine learning pipelines are sustainable and production ready.
1. Automate repetitive tasks
Automating repetitive operations in machine learning pipelines enhances efficiency and minimizes the risk of human error. Automation allows operations like data cleansing, feature extraction, and model checking to be done consistently with better workflow reliability. Scripting and cron jobs or more sophisticated workflow automation tools can perform these operations, minimizing the necessity for manual intervention.
Automated logging and monitoring also serve to give real-time visibility into pipeline run performance, immediately spotting differences. This frees data scientists to concentrate on model development and analysis instead of operational minutiae. Systematizing these procedures provides teams with greater consistency and quality between projects, leading to faster and more trustworthy deployments.
2. Leverage version control systems
Version Control System (VCS) application in machine learning pipelines is a recommended practice that guarantees tracking and managing code and data configuration changes. Git is a popular VCS that allows collaboration across teams with a complete change history. It allows for branching and merging, which supports simultaneous development activities without conflict.
Version control enables reverting back to past states, essential in debugging and rollback on deployment failures. It also leaves a clean audit trail for compliance and reproducibility, allowing the identification of which changes resulted in certain outcomes. Having these systems in place boosts collaborative productivity and provides continuity in machine learning projects.
3. Use strong error handling and logging
Strong error handling and logging are essential in ensuring operational stability within machine learning pipelines. Strong error handling looks for typical failure points, applying retries, notifications, and fallbacks to ensure pipeline integrity. Logging gives a detailed history of pipeline activity and failure, which is crucial in diagnosing and solving problems rapidly.
Error and log management tools must be implemented in pipelines to enable centralized monitoring. The use of logging frameworks helps to standardize records and enhance efficiency in debugging. The application of these practices guarantees that pipelines can withstand errors and enables long-term operations by offering insights into continuous improvement.
4. Monitor pipeline performance
Real-time pipeline performance monitoring is important for detecting inefficiencies and promoting effective operations. Key performance indicators such as processing time, resource utilization, and model correctness must be constantly monitored to guarantee conformity with business goals. Prometheus or Grafana can display real-time performance metrics graphically, enabling teams to immediately spot anomalies.
Periodic performance checks are required to adjust pipelines to evolving needs or growing data volumes. Automation of these checks increases efficiency by delivering real-time insights. Monitoring performance is part of pipeline design and enables teams to optimize resource utilization, improve operations, and guarantee consistent levels of performance.
5. Implement security and compliance standards
Protecting sensitive information and following regulatory standards is essential in machine learning projects. Pipelines should have encryption, user authentication, and access controls in place to protect data. Auditing periodically verifies compliance with standards such as GDPR or HIPAA, reducing risks and legal exposure.
Enforcing secure coding standards and vulnerability scans detects possible threats early on. Ongoing security log monitoring also strengthens defenses, and incident response plans are prepared to act quickly if intrusion does happen. By integrating security and compliance measures into their processes, organizations ensure that they retain trust and integrity in their machine learning solutions.
The path forward: Operationalizing ML pipelines for real-world impact
Implementing a well-structured ML pipeline is the key to moving from one-off models to scalable, production-ready systems. As businesses increasingly rely on data-driven decisions, the need for automation, consistency, and efficiency in model deployment is only growing.
By building robust machine learning pipelines, you attain the ability to respond quickly to market changes, scale insights across departments, and deliver real-time intelligence. Now is the time to bridge the gap between experimentation and execution, start building your ML pipeline architecture to turn your AI vision into measurable outcomes.
FAQs
1. What are the core components of a machine learning pipeline?
The core components of a machine learning pipeline are data ingestion, data preprocessing, feature engineering, model training, model evaluation, model deployment, monitoring and maintenance.
2. Can ML pipelines handle both structured and unstructured data?
Yes, ML pipelines are designed to process both structured data like tables and unstructured data such as images, audio, and text, using specialized preprocessing techniques.
3. How do ML pipelines enable predictive analytics?
ML pipelines enable predictive analytics by automating the flow from raw data to deployed models. This makes predictive analytics reliable, repeatable, and scalable.
4. What is the difference between data pipeline and ML pipeline?
A data pipeline focuses on extracting, transforming, and loading data. An ML pipeline includes this and adds steps like model training, evaluation, and deployment, making it part of the larger AI pipeline.
5. What is CI/CD pipeline for ML?
CI/CD in machine learning ensures continuous integration and continuous delivery of models by automating testing, versioning, and deployment through a structured MLOps pipeline.
6. What is the difference between ML and MLOps pipeline?
An ML pipeline handles model creation steps. An MLOps pipeline extends this by integrating version control, monitoring, and continuous delivery, enabling automation and governance for production-grade systems.