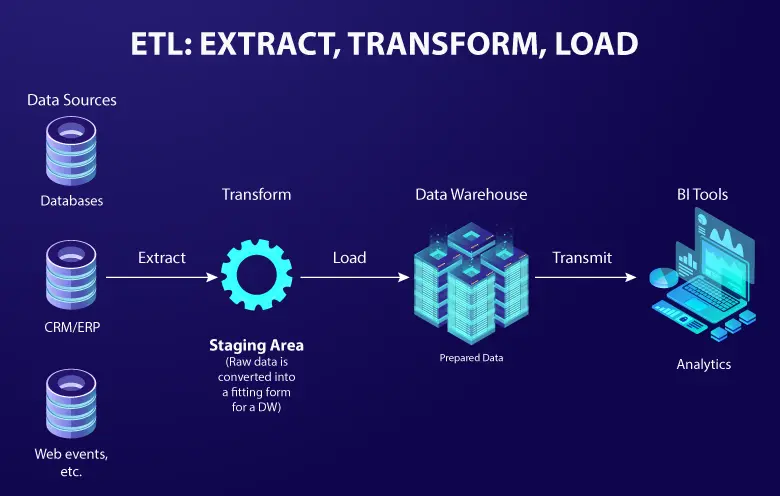
Most organizations already have the data they require. Data engineering best practices make it usable, reliable, and accessible. But as the volume, velocity, and variety of data continue to increase, simply having best practices in place is not enough in 2026 and beyond.
Data engineering trends are shifting fast with new architectures, automation capabilities, governance models, and AI‑driven tooling. Teams that once focused on pipelines and storage now face a broader data mandate.

That’s why understanding the top data engineering trends for 2026 will be a strategic advantage. Whether you modernize your stack, scale your data platform, or prepare for the next wave of AI‑powered innovation, the data engineering trends shaping 2026 will influence how you design, build, and operate data systems. This blog explains the most important trends you need to watch, helping you realize that you follow the modern data engineering approach essential for thriving in an AI‑driven future.
What are the top data engineering trends shaping decision-making in 2026?
Modern data warehouse trends are rapidly transforming how organizations design, manage, and scale data infrastructure. These shifts are driven by automation, cloud-native systems, real-time processing, and AI-powered tools.

1. Real-time data streaming and processing:
Traditional batch processing is no longer sufficient for organizations that requiring up-to-the-minute insights. Real-time data streaming and processing enable the ingestion and analysis of data as it is generated. This allows businesses to make faster, data-driven decisions. Technologies like Apache Kafka and Apache Flink have gained popularity for their ability to handle high-velocity data streams and perform real-time analytics.
Using Apache Kafka, you can build real-time streaming data pipelines and applications that adapt to data streams. For instance, if you want to track how people use your website in real-time by collecting user activity data, you can use Kafka. It helps store and manage streaming data while serving the applications that run the data pipeline.

By implementing real-time data streaming and processing solutions, you can unlock opportunities for real-time analytics, fraud detection, predictive maintenance and personalized customer experiences.
2. Cloud-native data engineering
The adoption of cloud computing has revolutionized the data engineering landscape. Cloud platforms like AWS, Azure and Google Cloud provide a scalable and cost-effective infrastructure for data storage and processing. Cloud-native data engineering leverages cloud services such as data lakes, data warehouses and serverless computing to build robust and flexible data pipelines.
For example, a data engineer could use Amazon Elastic Container Service (ECS) to deploy a containerized data pipeline that uses Kinesis to process and analyze real-time data from a sensor network. The data could then be stored in Redshift for analysis and machine learning models could be built with Amazon SageMaker.
Cloud platforms facilitate collaboration and integration, enabling data engineers to work efficiently and seamlessly with team members. They also connect data pipelines to analytics tools. Cloud-native data engineering offers benefits such as elasticity, scalability and easy integration with other cloud services. It allows organizations to focus on data engineering tasks rather than managing infrastructure, resulting in increased agility and faster time-to-market.
3. DataOps and Automation
Data engineering operations, or DataOps, is an emerging approach that applies DevOps principles to data engineering workflows. It emphasizes collaboration, automation and continuous delivery of data pipelines. By adopting DataOps practices, organizations can streamline their data engineering processes, improve data quality and reduce time-to-insights.
Automation plays a crucial role in DataOps by eliminating manual, repetitive tasks. Workflow orchestration tools like Apache Airflow and cloud-native services like AWS Glue provide automation capabilities for data pipeline management. Automated testing, monitoring and data engineering workflow reliability and efficiency. .
DataOps and automation work together to improve the efficiency and scalability of data engineering. You can automate data validation and testing using tools like Apache Airflow or Jenkins, ensuring continuous monitoring and adherence to predefined standards. Automation also simplifies data transformation and integration through workflows or pipelines by using ETL tools such as Apache Spark or AWS Glue. For example, you could use Apache Airflow to automate the process of loading data from a variety of sources into a data warehouse and then use Apache Spark to transform the data into a format that is suitable for analysis.
4. Machine learning and data engineering
The integration of machine learning (ML) with data engineering is transforming how organizations derive insights from data. Data engineers play a vital role in building robust ML pipelines that collect, preprocess and transform data for training ML models. They collaborate with data scientists to deploy these models into production and ensure scalability and reliability.
Incorporating ML in data engineering allows organizations to automate processes, make accurate predictions and gain valuable insights from complex data sets. Techniques like feature engineering, model serving and monitoring are becoming integral parts of data engineering workflows.
By using machine learning, data engineers can derive insights from data that would be difficult or impossible to identify manually. This can help businesses make better decisions and improve their operations.
For example, a data engineer could use machine learning to forecast demand for products or services. This information could then be used to optimize inventory levels and improve customer service.
5. Generative AI for data engineering
Generative AI (GenAI) is emerging as one of the most influential data engineering trends. It reshapes how teams build, manage, and optimize modern data ecosystems. Instead of writing every pipeline, transformation logic, or validation rule manually, data engineers can now use GenAI‑powered assistants to generate SQL queries, automate documentation, recommend data models, and create end‑to‑end workflows. Generative AI helps data engineers move faster and with accuracy.

By 2027, generative AI will evolve from a helpful tool into a foundational layer of the data engineering lifecycle. We will see:
- Self‑optimizing pipelines that adapt to workload patterns
- Metadata systems that continuously learn from usage patterns
- AI‑driven observability that predicts issues before they impact downstream analytics
Data engineering as a service
Data engineering as a service (DEaaS) is an emerging trend that allows organizations to outsource their data engineering needs to specialized service providers. DEaaS providers offer expertise in designing, building and maintaining data pipelines, allowing organizations to focus on their core business objectives. DEaaS can be a valuable tool for businesses that do not have the in-house resources to build and manage their own data pipelines.
DEaaS can be a valuable tool for businesses that do not have the in-house resources to build and manage their own data pipelines. DEaaS providers can help businesses to:
- Collect data from a variety of sources
- Store data in a secure and scalable manner
- Process data in a timely and accurate manner
- Analyze data to gain insights
DEaaS can also help businesses save time and money. By outsourcing their data engineering needs to a DEaaS provider, businesses can focus on their core competencies and avoid the costs of hiring and training in-house data engineers.
DEaaS provides scalability, cost-efficiency and access to skilled data engineering professionals. It eliminates the need for organizations to invest in infrastructure and hire dedicated data engineering teams. This makes it an attractive option for startups and small to medium-sized enterprises.
Turn challenges into opportunities with data engineering
Data engineering is an essential process that involves collecting, storing and processing vast amounts of data. It empowers organizations to enhance decision-making, boost operational efficiency and foster innovation. Let’s explore some specific examples of how data engineering benefits various companies:
Have you ever wondered how Netflix suggests movies and TV shows tailored to your preferences? Thanks to data engineering! By analyzing user data, Netflix personalizes its recommendations, keeping you engaged and satisfied.
Now, as an Amazon shopper, have you noticed how they always seem to have the right products in stock and deliver them promptly? Data engineering and modernization solutions play a key role in optimizing their supply chain. By analyzing customer demand data, Amazon ensures efficient inventory management, reduces costs and enhances customer satisfaction.
These examples highlight the significant impact of data engineering in the real world, enabling companies to provide personalized services, optimize operations and improve customer experiences. As data continues to grow in volume and complexity, the latest innovations in data engineering services will remain crucial for organizations seeking to stay competitive and thrive in today’s data-driven landscape.
To make the best of it, partnering with data engineering service providers allows businesses to quickly implement scalable solutions, access expert knowledge, and stay focused on core objectives—turning data challenges into growth opportunities.
FAQ’s
1. What is the future of data engineering?
The future of data engineering centers on automation, real-time pipelines, and cloud-native architectures. Engineers will focus less on manual integrations and more on scalable platforms. AI-assisted development, composable stacks, and unified analytics will define modern data engineering strategies.
2. How is AI impacting data engineering services?
AI is transforming data engineering by automating pipeline creation, improving data quality, and accelerating complex processing tasks. Machine learning enhances anomaly detection, metadata management, and system optimization. This shift allows teams to focus on higher‑value engineering work while delivering faster, more reliable, and more intelligent data services.
3. What is the role of DataOps and MLOps in data engineering?
DataOps and MLOps bring discipline, automation, and collaboration into data engineering processes. They streamline deployment, testing, version control, and monitoring across data and ML pipelines. Together, they ensure faster delivery, higher reliability, and consistent alignment between data, models, and business goals.
4. How can you optimize data engineering for better business performance?
Optimizing data engineering requires modernizing pipelines, improving data observability, and adopting scalable cloud‑native architectures. Automating repetitive tasks and enforcing strong data quality practices accelerates insight generation. These improvements help businesses reduce operational costs, enhance decision‑making, and unlock more value from their data assets.
5. Why should businesses choose Softweb Solutions for data engineering solutions?
Softweb Solutions delivers end‑to‑end data engineering expertise with modern architectures, automation capabilities, and AI‑driven innovation. Their tailored approach ensures scalable pipelines, trusted data, and faster analytics outcomes. Businesses benefit from deep technical experience, industry‑specific solutions, and a commitment to building future‑ready data ecosystems.