Turning data into insight demands more than just infrastructure, it requires intelligence, flexibility, and speed. Built on the foundation of Apache Spark, Databricks is a cloud platform and an all-in-one solution for every data requirement, including storage and analysis. It can integrate with visualization tools such as Power BI, Qlikview, and Tableau, create insights using SparkSQL, and build predictive models using SparkML. Databricks allows us to create concrete interactive displays, text, and code.
This data intelligence platform addresses the data processing complexity for data engineers and scientists so they can develop machine learning applications with Apache Spark through R, Scala, Python, or SQL interfaces.
Databricks integrates very well with the large cloud service providers, including Microsoft Azure, Amazon Web Services, and Google Cloud Platform. This enables business enterprises to manage large volumes of data and execute machine learning functions with no hassle.
Databricks consulting empowers organizations to unlock scalable data intelligence through tailored solutions and expert guidance.

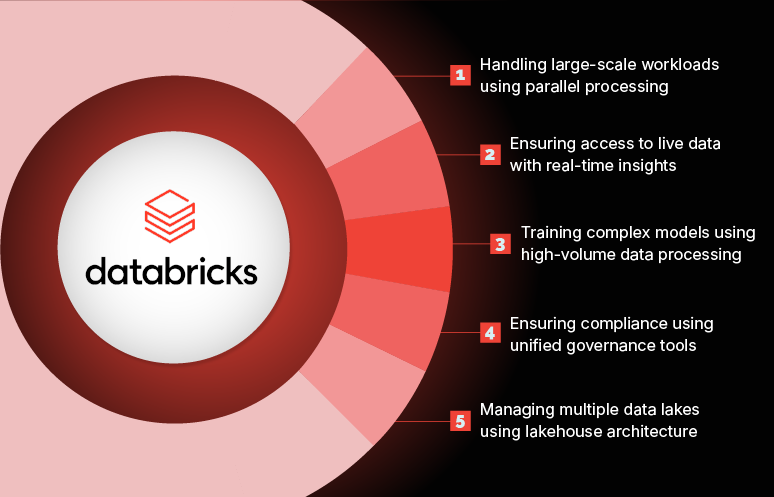
In this blog post, we will explore Databricks use cases along with some real-world examples. Let’s begin with the use cases.
1. Handling large-scale workloads using parallel processing
Managing large-scale data pipelines across various tools adds complexity, increases costs, and slows down actionable insights. These hurdles hinder the data processing speed, making it more difficult for your teams to make data-driven decisions in time.
Databricks optimizes performance with parallel processing that divides datasets into small tasks to accelerate insights and sustain productivity, even as your data grows. This eliminates lag and enables your teams to make quicker decisions without increasing complexity.
How Databricks increases data engineering efficiency
Converges workflows to remove bottlenecks:
Databricks unifies streaming and batch workloads in a single platform. It minimizes tool dependency, enabling your teams to access data more quickly and efficiently. Streamlined operations result in faster insights and informed decision-making.
Establishes organized workflows to prevent pipeline sprawl:
Databricks maintains organization and traceability of workflows via nesting of pipelines and parameterization of notebooks. This avoids operational ambiguity, allowing your teams to stay focused and prevent hold-ups in the data life cycle.
Tunes compute resources for optimal cost savings:
Databricks automatically tunes compute resources according to data volumes, ensuring that real-time and batch ETL operations are economical and high functioning.
Increases productivity with serverless compute:
Serverless architecture prevents downtime by controlling resources behind the scenes. This helps your teams concentrate more on important tasks, which would lead to quicker project completion and actionable insights.
Decreases cost while speeding up insights:
Optimizing data ingest and insight creation, Databricks reduces operational expense and waste. This accelerates decision-making and optimizes operational efficiency.
2. Ensuring access to live data with real-time insights
When every second matters, waiting long for data to be processed holds up critical decisions and affects performance. With real-time analytics, live data is made accessible, reducing delays and providing businesses with a clear, real-time view of what’s happening.
Databricks helps your teams to act without any delay by dynamically scaling processing capacity in real-time when streaming data arrives. This real-time scalability makes it possible to act on live data instantly, avoiding operational latency. And keeping your business prepared with the most current insights to make timely decisions.
How Databricks enables real-time analytics
Unite streaming and batch workflows:
Merge streaming and batch data in one ETL pipeline. This streamlines workflows, providing teams with quicker access to insights and allowing them to make real-time changes, such as correcting operational inefficiencies before they surge.
Offer real-time processing capabilities for mission-critical workloads:
Employ PySpark’s structured streaming alongside arrival functions to handle real-time data, particularly in sectors where tiny lag can lead to significant disruption. These capabilities enable processing of data in real-time so that it’s immediately available for analysis.
Process data on arrival for fast action:
Process data instantly upon entering the pipeline, enabling teams to act against real-time information. With immediate processing, your business can respond to fluctuating conditions, customer requirements, or internal processes faster, enhancing efficiency and decision-making.
3. Training complex models using high-volume data processing
Scaling AI and machine learning projects may not be an easy task. Organizations face challenges such as improper data management, limited compute, or shortfalls in machine learning proficiency. These challenges slow down AI projects and make it more difficult to create models that deliver meaningful business results.
Databricks assists with addressing these issues through dynamic scaling of compute resources for mass-scale AI model training. This adaptability enables your data scientists to handle massive datasets and intricate algorithms rapidly to execute iterations and experiments more quickly.
How Databricks empowers scalable AI/ML strategies
Unify workflows on one platform:
By bringing together the complete AI/ML lifecycle, from data ingestion to model monitoring, Databricks reduces the number of fragmented tools needed. This enables your team to work effectively, iterate quickly, and create AI models that have a direct influence on business outcomes.
Scale compute capacity for heavy workloads:
Databricks natively supports frameworks such as TensorFlow and Scikit-learn. This makes it easier to build deep learning and traditional ML models. Databricks also includes AI templates that makes it easy to identify and run AI use cases, allowing quicker and simpler AI implementation for organizations. This scalability allows your data science team to prototype, try, and train models without computational capacity limitations.
Handle the entire ML lifecycle with MLFlow:
Integrated MLFlow provides full lifecycle management for machine learning projects, from development to real-time deployment and monitoring. Together with Unity Catalog, it provides data governance and model traceability, so it is simpler to deploy secure, compliant, and trustworthy models.
4. Ensuring compliance using unified governance tools
Having secure, compliant, and high-quality data is essential to establish trust within your organization, particularly in highly regulated sectors. Appropriate data governance reduces risk while ensuring data quality and trustworthiness.
Databricks fulfils these requirements with Unity Catalog, a governance solution that unifies access control, metadata management, and monitoring of data quality. This supports your teams in sustaining compliance, enhancing data integrity, and optimizing overall operations.
How Databricks keeps your data complete and compliant
Centralize governance in a single platform:
Unity Catalog unifies metadata management, access control, and data quality monitoring as a single solution. This eases data management without adding complexity. Real-time data quality enforcement, like marking invalid values, instils trust in your data and lets your team concentrate on data-driven decision-making.
Maintain regulatory compliance easily:
Unity Catalog tracks and monitors data access, ensuring adherence to industry standards whether you’re handling sensitive data like PII or HIPAA-protected information. United with Delta Lake, Databricks helps enforce data retention policies and manage audits. This allows your business to stay compliant without adding extra complexity.
Enable innovation with trusted data:
Governance safeguards your data and fuels innovation. Unity Catalog provides transparent data lineage, table definitions, and metadata mapping, enabling your team to see data movement clearly across systems. This transparency inspires teams to use self-service analytics and venture into new innovative solutions with reliable data.
5. Managing multiple data lakes using lakehouse architecture
Dealing with a combination of structured and unstructured data within a conventional data warehouse is bound to become inefficient, costly, and cumbersome.
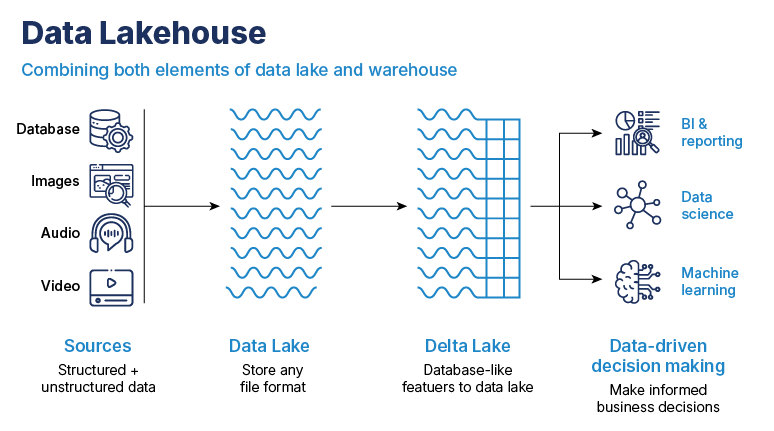
With the lakehouse architecture of Databricks, there’s no need to compromise between flexibility and control anymore. The lakehouse combines the best of both data lakes and warehouses to allow you to handle everything, from raw logs to refined reports on a single platform.
How Databricks empowers lakehouse architecture
Handle every type of data efficiently:
From structured business information to unstructured logs and multimedia data, Databricks stores and processes all the data on a single platform. This eliminates the requirement for multiple systems as well as simplifies the workflows, enabling your team to concentrate on creating actionable insights instead of operating different systems.
Improve performance with Medallion Architecture:
The Medallion Architecture structures data into bronze, silver and gold layers, optimizing it to use with BI tools. The gold layer provides ready-to-use, clean data, easing the load for BI systems and speeding up access to insights.
Control expenses without compromising performance:
Databricks supports dynamic scaling of compute resources, so you fine-tune power as required. This avoids over-provisioning or overspending on inactive resources, while dynamic scaling keeps you cost-effective, even under large data processes.
Real-world use cases of Databricks showcasing how companies are using it
When evaluating any data platform, one of the most practical ways to gauge its value is by seeing how it performs in action. Use this perspective to think beyond features, toward outcomes, impact, and possibilities for your organization.
Texas Rangers baseball team utilizes the Databricks to take data at hundreds of frames per second to analyze player mechanics. This helps them optimize personnel decisions and injury prevention, among other applications.
Minecraft, one of the most popular games globally, cut processing time by 66% with the transition to Databricks. They utilize data and AI to improve the gaming experience.
Blue River Technology, a subsidiary of John Deere, leverages data and artificial intelligence to drive the new autonomous tractor. The tractor is fitted with 360-degree cameras and backed by AI for instant image processing.
Ahold Delhaize USA is the U.S. division of the global food retailer Ahold Delhaize. They developed a self-service data platform with Databricks to help their engineers create pipelines that facilitate data science and AI/ML-based applications. ADUSA also employs the DI Platform to enable customer personalization, loyalty programs, food waste reduction, environmental initiatives, logistics, forecasting, and inventory management.
Unilever: The international consumer goods company employs Databricks in various ways, including:
- Unilever’s metadata system, Blueprint, is a breakthrough in Unilever’s lakehouse management with significant capabilities. The system unified Unilever’s engineering team and accelerated development by tenfold. Supporting more than 3,000 users with its downstream features, Blueprint greatly improved Unilever’s data engineering, establishing new standards of efficiency and scalability for its lakehouse architecture.
- Unilever moved to Unity Catalog to democratize its massive data sources in a secure, governed manner. As Unilever produced its Unity Catalog tooling, it unlocked outstanding new opportunity, particularly with Lakehouse Federation and Delta Sharing.
- Unilever enhanced the current forecasting processes by using ML predictive models to forecast several key business metrics at different levels of granularity. The driving force behind this is a reusable predictive framework Unilever built and developed on Databricks that can be reused for different time series forecasting scenarios to achieve development efficiencies and simplified maintenance.
Shell, a global group of energy and petrochemical companies, employed the Unity Catalog and a business-owned data product strategy to address the challenges they faced with data strategy and governance. They used analytics, Power BI, ML models, and AI for data governance.
Albertsons is one of the largest food and drug retailers in the United States. They offer a serving model for an internal price analytics application that initiates thousands of models with a single click and anticipates a response in near real-time. The grocery store accomplished this daunting requirement using its in-house developed model serving framework and Databricks serverless computing.
AT&T is one of the largest telecommunications companies in the world. They utilize Databricks to automate and speed up new data products, ranging from automated pipelining through Delta Live Tables to serverless Databricks SQL warehouses and AI/ML applications.
Mastercard is an American multinational payment card services corporation. They use the Databricks Data Intelligence Platform as part of its multi-step journey to deepen its commitment to identifying AI’s capability as a foundational component for commerce.
Myntra is India’s largest e-commerce store for fashion and lifestyle product. They shifted from a cloud data warehousing and Hive to Delta Lake to improve clickstream data analysis of petabytes of data. The re-architecting is directed towards scalability improvement, cost savings, and performance.
Take the next step toward a smarter data strategy
As data continues to drive innovation across industries, it becomes essential to adopt platforms that offer agility, scalability, and intelligence. Databricks empowers organizations to reduce operational complexity, break down data silos, and unlock business value faster.
It works seamlessly across major cloud platforms like Azure, AWS, and Google Cloud, giving teams the flexibility to build on their existing infrastructure. Databricks delivers a unified approach to drive results, whether you’re scaling analytics or operationalizing AI.
Connect with our experts to know how Databricks would help you accelerate time to insight, boost collaboration between data scientists and analysts, and future-proof your data infrastructure.



