

Deep learning has turned computer vision into a real-time decision engine.
From identifying defective parts on production lines to analyzing aerial drone footage for infrastructure damage, deep learning solutions for computer vision enable systems to interpret visual data the way businesses need – fast, adaptive, and at scale.
These systems used to depend on explicit instructions for every edge case. Now, they learn from examples and continuously improve. Therefore, it is possible to shift from static rule-based recognition to dynamic visual understanding.
Across industries – manufacturing, healthcare, supply chain, and logistics – this evolution is driving automation, faster response times, and fewer errors. This blog post will explore how deep learning powers these changes. We will look at how problem formulation works, what models bring this capability to life, and how different industries deploy deep learning-based computer vision systems to meet their business goals.
Understanding deep learning in computer vision
Traditional computer vision services require engineers to define what a ‘car,’ ‘tumor,’ or ‘scratch’ looked like, pixel by pixel. Deep learning replaced this with data-driven learning. Rather coding rules, we train models to learn patterns.
At its core, deep learning for computer vision uses convolutional neural networks (CNNs), recurrent networks, and transformer-based models. These architectures process raw pixels and extract abstract features that help classify, detect, or segment objects in images or videos.
Below are three qualities that make deep learning effective for computer vision applications:
- Adaptivity: It adjusts to new visual contexts – like shadows, angles, or textures – without manual reprogramming.
- Accuracy: With enough data, deep learning models outperform traditional methods in identifying subtle anomalies or patterns.
- Real-time inference: When deployed with optimized hardware, these models process inputs on the fly – essential for surveillance, autonomous vehicles, or AR applications.
The power lies in how deep learning mimics visual cognition.
Framing the right problem: The first step to success
Before selecting a deep learning model or curating data, it is important to formulate the problem.
How you pose the problem determines everything that follows. Are you classifying defect types? Localizing pedestrians in traffic feeds? Counting product units on a conveyor belt? Each scenario demands a different problem framing.
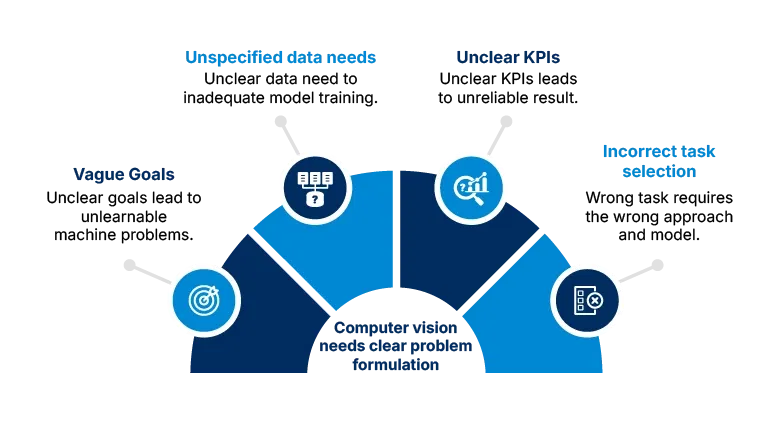
For example, saying, “we want to detect defects” is too vague. A better formulation might be:
“We aim to identify hairline cracks on turbine blades in varying lighting conditions and reflectivity using bounding boxes, with less than 1% false negatives.”
A well-defined problem helps you:
- Choose the right model (e.g., ResNet for classification, YOLO for detection)
- Decide on the data type and annotations
- Set evaluation metrics that align with business needs
The benefits of deep learning solutions for computer vision depend on how well you structure the problem.
Choosing the right deep learning model: You have won half the battle
The deep learning model you choose dictates how your visual data will be interpreted, what patterns it will recognize, and how well it adapts to real-world conditions.
At the heart of computer vision tasks are CNNs. These models capture spatial features like edges, textures, shapes, and so on from images. CNNs are ideal for classification, object detection, and segmentation.
Not all vision tasks are static. Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) analyze video and time-sequenced frames. They preserve temporal context, essential for applications like traffic monitoring or behavior analysis in surveillance footage.
In parallel, Generative Adversarial Networks (GANs) contribute synthetic intelligence. These models generate realistic images. They bridge data gaps through augmentation, restoration, or simulation. From filling in occluded visuals to training rare-event classifiers, GANs help models learn more from less.
For noise-prone or sparse environments, Autoencoders and Restricted Boltzmann Machines (RBMs) play a different role. They compress, denoise, and extract hidden patterns without requiring labeled data. These models are recommended in unsupervised learning scenarios where data quality or quantity is constrained.
To summarize the strengths of different deep learning models:
| Deep learning model | Primary use in computer vision | Key strength |
|---|---|---|
| CNN (Convolutional Neural Network) | Image classification, object detection, and segmentation | Captures spatial features and patterns |
| RNN (Recurrent Neural Network) | Video analysis and sequence labeling | Remembers temporal context across frames |
| LSTM (Long Short-Term Memory) | Action recognition and video captioning | Handles long-term dependencies in sequences |
| GAN (Generative Adversarial Network) | Image synthesis and data augmentation | Generates realistic images, fills missing data |
| Autoencoder | Denoising and feature compression | Learns compact representations without labels |
| RBM (Restricted Boltzmann Machine) | Dimensionality reduction and unsupervised learning | Extracts latent visual features |
| MLP (Multilayer Perceptron) | Basic classification | Simple tasks with small-scale datasets |
| RBFN (Radial Basis Function Network) | Function approximation | High responsiveness to localized patterns |
| SOM (Self-Organizing Map) | Visual clustering and pattern discovery | Intuitive data visualization |
| DBN (Deep Belief Network) | Pre-training deep models | Layer-wise unsupervised learning |
In business terms, it means CNNs can identify invisible defects in manufacturing. GANs can reconstruct low-quality medical scans in healthcare. LSTMs can track moving goods with context-aware intelligence in logistics.
Choosing the deep learning model is not the endgame, of course. In computer vision, they are meant to translate into real-world impact.
Deep learning-driven computer vision application areas across industries: Turning visuals into business value
From factory floors to operating rooms, deep learning-based computer vision applications solve complex visual challenges that traditional methods could not handle. The following examples demonstrate how organizations can achieve measurable improvements in efficiency, accuracy, and decision-making speed through these solutions.
Manufacturing
- Product design optimization
Manufacturers have long relied on trial-and-error or static CAD evaluations to validate product designs. This limits the ability to detect issues early. Deep learning-based computer vision solutions allow for continuous design evaluation by comparing current designs against extensive databases of high-performing patterns. This approach offers an intelligent path to refine product geometry, material use, and assembly processes with greater confidence and precision. - Visual inspection of equipment and processes
Inspection of machinery and processes often hinges on human oversight, which tends to vary with experience and fatigue. With deep neural networks trained on thousands of defect types, visual inspection systems can monitor equipment in real time. Subtle surface defects, wear marks, or operational anomalies can be identified much earlier than manual inspections allow. - Predictive maintenance
Unexpected equipment failures continue to be a major bottleneck for throughput in manufacturing. Deep learning models can evaluate live video feeds or high-speed image captures to detect early warning signs – like microfractures or thermal inconsistencies – before they escalate. When paired with time-series forecasting models, this visual data enables predictive maintenance schedules tailored to specific machine behaviors.
Healthcare
- Medical imaging diagnostics
Radiologists often face diagnostic ambiguity when interpreting X-rays, CT scans, or MRIs, especially when early symptoms appear subtle or scattered. Deep CNNs, such as ResNet and DenseNet, have shown a potential to match or exceed expert-level accuracy in detecting pathologies like pneumonia or intracranial hemorrhage. These systems learn spatial hierarchies of features, allowing them to identify disease patterns that may elude even seasoned specialists. - Surgical assistance
The complexity of surgical workflows demands constant visual awareness from the operating team. Deep learning-based CV systems can identify and track surgical tools, anatomical landmarks, and tissues in real time, minimizing accidental errors. Studies from Yale University show that integrating such systems in minimally invasive procedures reduces surgery duration by up to 20% and decreases complication rates by over 25%. - Cancer screening
Screening for early-stage cancers using imaging is often constrained by access to radiological expertise. In recent initiatives, deep learning systems have been trained to detect precancerous abnormalities in breast, cervical, and oral tissue scans. These systems outperform manual screenings in both speed and sensitivity and, when deployed across public healthcare setups, can significantly reduce diagnosis delays.
Energy
- Infrastructure monitoring
Pipelines, substations, and transmission lines span long distances and require regular inspection. Manual assessments often miss localized faults or surface-level damage. Deep learning-based computer vision systems can automate drone or satellite-based inspections. These systems detect structural weaknesses such as corrosion, thermal hotspots, or vegetation encroachment, which are precursors to large-scale failures. - Predictive maintenance
Thermal cameras combined with deep CNNs allow for predictive modeling of component health in turbines, transformers, and engines. Unlike threshold-based systems, deep learning can analyze contextual and sequential visual cues to estimate wear progression. This approach improves the accuracy of maintenance predictions and reduces unnecessary interventions. - Solar panel inspection and fault detection
Visual degradation of solar panels – such as cracks, delamination, and hotspot formation –can significantly reduce energy output. Manual inspection is inefficient, especially in large-scale solar farms. Deep learning models powered by drone imagery and computer vision tools enable automated, high-resolution diagnostics.
Supply chain and logistics
- Inventory management
Manual inventory counts result in data mismatches, especially in fast-moving environments. Deep learning-enabled vision systems can interpret shelf images or aerial warehouse footage to calculate inventory in real time. These systems track quantity, shelf layout, placement errors, and stock rotation timelines, improving overall warehouse accuracy. - Warehouse automation
Autonomous sorting and picking systems rely heavily on visual recognition. Models like YOLO or EfficientDet can detect and classify packages, cartons, or individual SKUs on conveyor belts. Paired with robotic arms, these models enable seamless execution of repetitive logistics tasks with minimal human oversight. - Supply chain visibility
Shipping discrepancies and bottlenecks remain a blind spot for logistics teams. Visual tracking of goods – from first mile to last – adds contextual information that barcodes or RFID systems cannot provide. CV systems can analyze footage to identify transit damage, improper storage, or loading issues, helping managers act swiftly and accurately.
Semiconductor
- Wafer defect detection
High-precision manufacturing of semiconductor wafers demands equally precise inspection. Deep learning systems trained on hyperspectral and high-resolution imagery can detect structural defects invisible to the naked eye. Studies from Purdue University demonstrate that ResNet-based deep learning models achieve up to 96% accuracy in detecting submicron defects on semiconductor wafers. - Process optimization
Deep learning vision systems monitor photolithography, etching, and doping stages. By correlating visual patterns with yield data, these systems help engineers make precise process adjustments. This dynamic feedback loop improves production throughput and reduces defect rates. - Equipment monitoring
As with other precision industries, machinery in semiconductor fabs must operate under tight tolerances. Computer vision models provide live visual diagnostics of tools and surfaces, helping detect misalignment, tool wear, or overheating. These insights feed into preventive maintenance models that extend the equipment’s lifecycle and maintain cleanroom standards.
Turn your static visuals into smart decisions
Deep learning is enabling computer vision to go beyond basic image recognition. Whether you detect defects before they reach customers, track shipments in transit, or support medical diagnostics, these technologies help you reduce errors, speed up processes, and improve real-time decision-making.
Every system has its own path forward. Let’s talk about how deep learning fits yours.
Whether you need to build a custom solution or optimize what you already have, we can help. Fill out this form, and our consultant will contact you in two business days.



