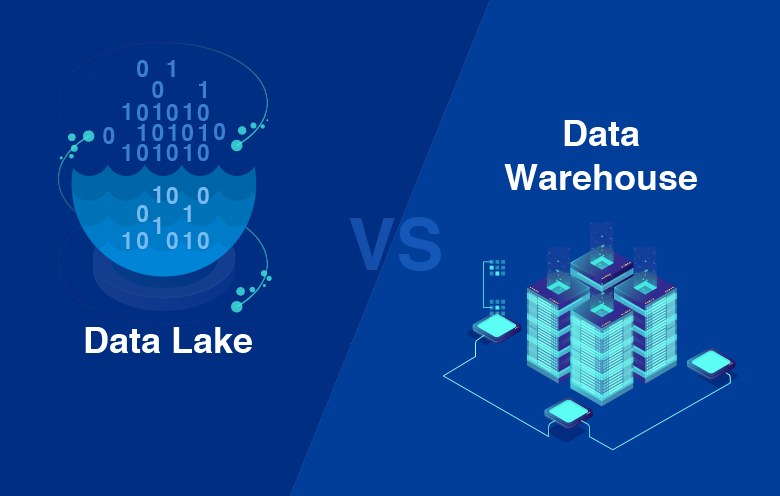
With the increasing amount of data and its sources, it has become critical for businesses to use that data to make informed decisions. However, it is equally important to identify the correct datasets for further analysis.
Companies face challenges like:
- Disparate data sources
- Lack of data management
- No visibility into the data
- Identifying what data to use
- Maintaining a central data repository
Data pipeline processes are the answers that can efficiently address the issues mentioned above. There are two types of data pipelines – ETL and ELT.
With ETL, you extract the raw data, transform it and then load it into a central data repository. On the other hand, ELT lets you extract the data and load the raw data into the repository. The data is then transformed for further analysis.
To understand which data pipeline to leverage, read our blog on ETL vs ELT.
Both processes need a data repository to store raw or structured data that can be used for multiple purposes, such as machine learning (ML), artificial intelligence (AI), business intelligence (BI) and more. Hence, it is essential to understand the importance of data repositories, their types and their differences.
How does a central data repository help businesses with improved advanced analytics?
A central data repository can assist you by combining data from multiple sources into a single location. This provides a centralized view of the data, making analysis easier and more efficient. The data can also be standardized, cleansed and integrated. This ensures that the insights drawn from it are accurate and consistent.
By having a single source of truth, businesses can make data-driven decisions and gain valuable insights into their operations. Additionally, a central repository can improve data governance and security. This ensures that sensitive data is protected and used in a controlled manner.
Cloud warehousing solutions are set to grow at nearly 15% CAGR. – Global Market Insights
There are several types of data repositories like data marts, data warehouses, data lakes and more. These all serve different purposes and based on your requirements can be leveraged for various use cases.
What is a data warehouse?
A data warehouse is a centralized repository for storing and managing large amounts of structured data, designed for fast query performance and business intelligence workloads. The data in a data warehouse is typically modeled and organized for specific business purposes.
Data warehouses are optimized for reading and analyzing data. They are designed to provide quick and efficient access, allowing users to make data-driven decisions.
A data warehouse is used when you need to analyze large amounts of historical data that has been aggregated from multiple sources. Data warehouses are designed to store large volumes of data for an extended period.
Key benefits of data warehouses
- Centralized: All the data from various sources is stored in one place.
- Access to historical data: Data is stored in a way that it can be analyzed over a long period.
- Data integration: Data is integrated from different sources and transformed into a common data model.
- Analytical capabilities: Data is stored in a structure that can be analyzed for business intelligence and decision-making.
- Scalable: Data warehouses are designed to handle large amounts of data and can easily scale as the data grows.
What is a data lake?
A data lake is a central repository that stores structured, semi-structured and unstructured data at any scale. It can store data in its native format and process any variety of it, ignoring size limits.
A data lake can be used when you need to analyze large amounts of diverse data and require flexible advanced analytics. It is also a great fit for big data analytics, as it stores and efficiently processes large amounts of data.
Key benefits of a data lake
- Data ingestion: Data is ingested into the data lake from various sources such as databases, logs and APIs.
- Data accessibility: The data is stored in its raw form, making it accessible to different teams and tools.
- Multi-tenancy: A data lake can support multiple tenants, making it suitable to use in a multi-party environment.
Data warehouse vs data lake: Key differences
| Storage | Data lake | Data warehouse |
| Use case | Predictive analytics, machine learning, data visualization, BI, big data analytics and more. | Data visualization, BI and data analytics. |
| Technologies | Data lakes are often used in conjunction with Hadoop and Spark to process the data. They can store data in a variety of formats, such as JSON, XML and CSV as well as binary formats like Avro and Parquet. | Data warehouses are typically used for reporting and analysis, and can support a variety of data analysis techniques, such as ad-hoc querying, predictive analytics, and data mining. |
| Data pipeline process | In ELT process, the data is extracted from its source for storage in the data lake and structured only when needed. | In ETL process, data is extracted from its source, transformed, then structured so it’s ready for analysis. |
| Cost | Data lakes are less time-consuming to manage, which reduces operational costs. | Data warehouses cost more than data lakes as they require more time to manage. |
| Schema | Schema is defined after the data is stored, making the process of capturing and storing the data faster. | Schema is defined before the data is stored. This lengthens the time it takes to process the data, but once complete, the data is ready for consistent use across the organization. |
Softweb Solutions’ approach to data repository management
Data scientists at Softweb Solutions have in-depth knowledge of data pipeline processes, data repository management, data analytics, business intelligence and more. We offer the following data warehouse and data lake solutions:
- Architecture design: Ensure optimal performance, scalability and security.
- Implementation: Implement data warehouse and data lake solutions on cloud platforms such as AWS, Azure and GCP, as well as on-premises solutions.
- Data integration and migration: Integrate data from multiple sources into a single repository and migrate from existing data storage solutions.
- Analytics and reporting: Set up analytics and reporting solutions to gather insights from the data.
- Management and maintenance: Efficiently manage and maintain data warehouse and data lake solutions to ensure optimal performance and security.
Data lake vs data warehouse: Which one should decision-makers choose?
Data lakes and data warehouses – both have their strengths and weaknesses. The choice between the two depends on the specific needs of an organization. Align your end goal with your storage needs to select the best option.
A data lake is better suited to store raw, unstructured data and performing batch processing. A data warehouse is optimized for storing structured, processed data and performing quick, complex queries for business intelligence purposes. For data warehouse and data lake consulting services, you can contact our data analysts.