Modern businesses generate vast amounts of data. And many companies fail to recognize the value of data analytics.
“68% of data available to businesses goes unleveraged.” – Seagate’s Rethink Data Report
Every bit of unused data represents untapped business value.
Businesses leveraging big data saw profit increases of 8% and cost reductions of 10%. Source: A BARC research report
These statistics demonstrate that data analytics solutions deliver substantial ROI. However, many organizations collect large volumes of data without knowing how to store it effectively for future use. This is where data warehouses and data lakes become essential.
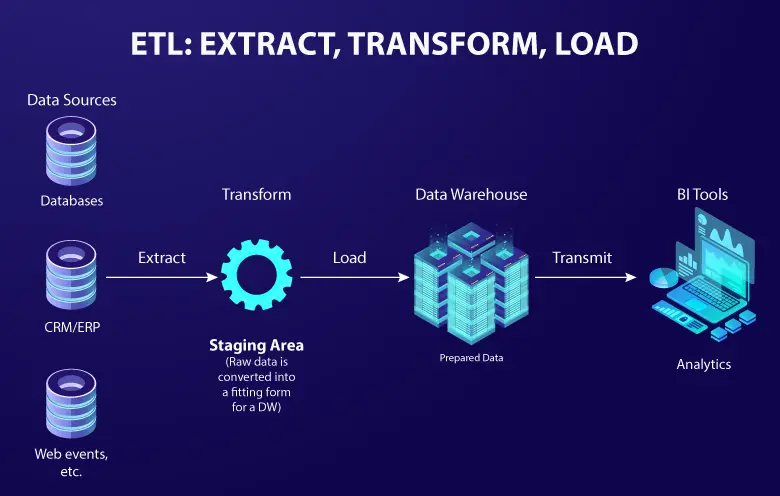
Data warehouses accelerate access to diverse datasets from multiple sources and enable decision-makers to derive insights that inform better business and marketing strategies. Implementing a data warehouse requires understanding the difference between ETL (Extract, Transform, and Load) and ELT (Extract, Load, and Transform). Both approaches allow companies to consolidate data from multiple databases into a single repository, but there’s a slight difference between these data pipeline processes.
Let’s explore the key differences between ETL and ELT.
Understanding data pipeline
A data pipeline has a sole purpose – extracting data from the source and sending it to the destination. In this case, the source is the data collected from disparate systems and the destination is where the data is loaded into. Building data pipelines involves data processing to ensure proper data governance. There are two types of data integration processes: ETL and ELT.
What is ETL in data integration?
When raw data is extracted from various sources, it is imperative to clean that data into a meaningful and comprehensible format. Once the data is formatted, it is then transferred to a data warehouse for further analysis. This entire process is called ETL – where data is first extracted, transformed and then loaded into a data repository.
ETL routes the extracted data to a processing server, and then transforms the non-conforming data into SQL-based data. This ensures adherence to compliance. Some of the ETL tools to leverage:
- Talend Open Studio
- AWS Glue
- Azure Data Factory
- Google Cloud Dataflow
- Microsoft SSIS
Read more to learn how Azure Data Factory accelerates data integration process.
Benefits of ETL
- Scalability: As data is structured and transformed prior to loading, the ETL process makes data analysis on a single, pre-defined use case scalable and faster.
- Compliance: ETL makes it easier for users to adhere to rules and regulations like HIPPA, GDPR, etc., by omitting any sensitive data prior to loading in the target system.
- Faster analysis: ETL ensures more efficient data queries than unstructured data, which leads to faster analysis.
- Environment flexibility: ETL can be implemented on both on-premises as well as in a cloud environment.
What is ELT?
After the data is extracted, it is loaded into a data warehouse in its raw form. It is then transformed into the storage itself for further analysis. This entire process is called ELT – where data is extracted, loaded in a data repository and then transformed into a more understandable format.
ELT data integration process includes data cleansing, enrichment and data transformation that occur inside the data warehouse itself. The processing is done by a database engine rather than an ETL engine. Some of the ELT tools to use:
- Amazon Snowflake
- Amazon Redshift
- Google BigQuery
- Microsoft Azure
Benefits of ELT
- Flexible data analysis: Users can leverage data analysis in real-time without waiting for further data to be extracted and transformed.
- Lower maintenance cost: As the transformation process is cloud-based, ELT offers a lower cost of maintaining the infrastructure.
- High availability of data: All data is available at the data lake. This allows tools to access even unstructured data with loaded data.
- Faster loading: Data is loaded at the data lake as soon as it is available without it being transformed first.
ETL vs ELT: Let’s look at the detailed comparison:
| Parameters | ETL | ELT |
| Transform | Raw data is transformed on the processing server. | Raw data is transformed inside the target system. |
| Data storage | ETL is the traditional process for transforming and incorporating structured or relational data into a cloud-based or on-premises data warehouse. | ELT supports data warehouses, data lakes, data marts, etc. |
| Size and type of data | ETL can be leveraged for small data sets which require complex transformation. | ELT is suited for both structured and unstructured data of any size. |
| Security | Pre-load transformation can eliminate PII. | As ELT loads the data directly, more privacy safeguards are required. |
| Code-based transformation | Transformation occurs on the secondary server. As a result, transforming large datasets can take longer. | Transformation is performed in databases. The transformation step takes little time but can slow down the querying and analysis processes |
| Compliance | ETL is better suited for compliance with GDPR, HIPAA, and CCPA standards. | There is more risk of a security breach in the case of ELT. Hence, it is difficult to comply with GDPR, HIPPA, etc. |
| Data output | The output only comprises of structured data. | ELT process offers structured, semi-structured and unstructured output data. |
| Re-queries | As data is transformed before entering the destination, re-query is not possible. | Raw data is directly loaded in ELT, making it possible to run re-queries multiple times. |
| Cost | As it requires an additional server, the cost is comparatively higher. | With no extra server required, the cost is low. |
| Maintenance | The extra server needs more maintenance. | With fewer systems, the maintenance burden is reduced. |
| Hardware | The traditional, on-premises ETL process requires more hardware. | As the ELT process is cloud-based, no additional hardware is required. |
How is ETL different from the ELT process?
ETL and ELT vary in two fundamental aspects. The first distinction is the location where data transformation occurs, and the second involves the way data warehouses store data.
- ETL performs data transformation on an independent processing server, whereas ELT carries out transformation directly within the data warehouse.
- ETL doesn’t move raw data into the data warehouse, whereas ELT transmits raw data straight to the data warehouse.
- ELT delivers faster data processing compared to ETL. ETL includes an initial transformation phase before loading data into the destination, which presents scaling challenges and lowers performance as data volume increases. ELT transfers data immediately into the target system, performing transformation simultaneously.
- With ETL, the data ingestion process experiences delay due to transforming data on an isolated server prior to the loading phase. ELT enables quicker data ingestion, since data isn’t routed to a secondary server for restructuring. Data loading and transformation can occur parallelly with ELT.
When should you use ELT instead of ETL?
Determining whether to implement ETL or ELT hinges on multiple factors, including your data’s characteristics, compliance requirements, infrastructure, and budget.
- Data structure: When data is highly structured, ETL guarantees it’s clean and usable before loading. For unstructured data or extensive data lakes, ELT may be more suitable.
- Technology stack: Organizations using on-premises or traditional databases frequently utilize ETL. Whereas cloud-based systems with scalable storage support ELT.
- Compliance: ETL may be supported in industries with rigorous data quality and governance requirements, since data is cleansed and structured before storage.
- Latency requirements: For real-time or near-real-time data access, ELT enables faster access, loading data without immediate transformation.
- Cost considerations: ELT may incur costs in terms of storage and transformation within the cloud, whereas ETL can minimize costs by transforming data outside the storage environment.
ETL vs ELT: What to choose?
ETL has been around since the 1970s as the amount of heterogenous data kept growing. With the rising demand for data warehouses, ETL became more essential. With the emergence of cloud computing and cloud storage in the 2000s, data lakes and data warehouses caused a new evolution called ELT.
For faster computing, ELT is the best suitable approach. However, ETL is preferred for better security and scalable data analytics. ETL and ELT, both have their pros and cons. Hence, based on your requirement, you can decide to leverage either of the data pipeline processes. It is advised to take the help of a service provider that is an expert in the field of data analytics and data science. This will enable you in better decision-making and will allow you to achieve improved ROI. To get a better understanding of the data integration process, talk to our data scientists.