AI models are the engines behind today’s data-driven insights. Trained on historical data, they uncover patterns, forecast outcomes and automate decisions across every business function. From straightforward classifiers to complex generative networks, each model type solves a distinct challenge.
Different businesses have different needs, and a single AI model cannot address them all. There are many AI models, such as generative models that produce new content, task-based models tackle specific problems from examples, and rule-based, statistical or neural approaches reason and carry out actions.
Before implementing AI-based system, it is important for a business to evaluate their needs and match it with the proper AI-model and the solution it offers. In this blog post, we will discuss different AI models, figure out where they are most helpful, and which businesses can benefit from them the most.
We’ll begin by answering two most fundamental questions: What is an AI model and how does it work?
What is an AI model?
An AI model is a software program that has been trained on gathered data to identify patterns and then make predictions or take decisions. These models are powered by various algorithms designed to achieve different objectives without human intervention. AI models can make autonomous decisions, rather than simulate human intelligence.
AI models differ in the decision logic they apply. Choosing the right model depends on matching that logic to your specific business challenge. If a system is complex, multiple models run in parallel, applying learning techniques such as blending, boosting and bagging to deliver the desired results.
AI has evolved significantly since the earliest models powered by vacuum tubes in the 1950s, moving through semiconductor-based integrated circuits and today’s GPUs. AI models need the right hardware to operate. But AI models are evolving at a faster rate than hardware capabilities needed to support them. This has led to the development of foundation models. These models are pre-trained on diverse data sets and used for many downstream tasks. Examples of these models include Generative Pretrained Transformer (GPT) and Bidirectional Encoder Representations from Transformers (BERT).
OpenAI’s GPT-5 series builds on that progress with stronger reasoning and new developer controls that shape length, style, and structured outputs. ChatGPT now routes between a fast default model and a deeper “GPT-5 thinking” mode based on task complexity, which raises reliability for production use.
Algorithms vs models
Before examining various AI model types, it is useful to clarify how a model differs from its underlying algorithm.
| Algorithms | Models |
|---|---|
|
An algorithm is like the formula you enter in a spreadsheet. It lays out the steps for processing data, for example, calculating an average or finding a trend. |
A model is the result you get after you apply that formula to your actual data. It holds the patterns and insights drawn from your historical figures, ready to make predictions on new information. |
In simple terms, an algorithm defines the specific steps for processing data, while a model is the outcome of applying those steps to real records.
How does an AI model work?
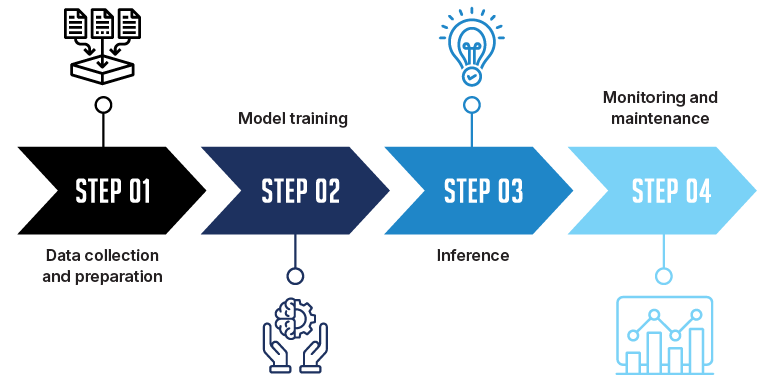
An AI model moves through four well-defined stages, turning collected data into dependable predictions.
-
Data collection and preparation
The process starts with assembling records from reliable sources, such as transaction histories or website activity logs. The data is examined to correct errors and fill in any missing values. After that, values are scaled to a consistent range. The finished dataset is divided into training, validation, and test sets. The training set teaches the model, the validation set guides model choices, and the test set provides a final, unbiased check.
-
Model training
The training portion is processed repeatedly by a chosen algorithm. With each pass, the algorithm adjusts its internal settings to capture the relationships that explain the data. Once these adjustments settle, the model is tested on data it has not seen before to ensure its accuracy.
-
Inference
Once validated, the model is placed into regular use. It ingests new data and uses its trained parameters to generate classifications, forecasts, or other predictions automatically.
-
Monitoring and maintenance
During daily operation, the model’s output is compared with real outcomes. When accuracy declines or the data environment shifts, the team gathers updated information, and the training cycle is repeated. This routine ensures the model remains precise and aligned with current business goals.
AI model types and architectures
Artificial intelligence covers a range of model families, each suited to a specific type of problem. Knowing these families helps teams match business questions to the right approach. The groups below range from classic classifiers to advanced diffusion networks that create high-quality images. The unique capabilities of each model show how they can collaborate within a modern solution.
-
Task-based AI models
Task-based models focus on a single well-defined objective. Teams choose these models when strict deadlines must be met, and the goal is clearly stated. Each model is configured to solve one specific problem, such as detecting a faulty component or forecasting next quarter’s revenue.
- Classification sorts each record into a category, for example marking a transaction as legitimate or fraudulent.
- Regression estimates a numerical outcome, such as projected sales for the next quarter.
- Clustering groups records that share similar traits, helping analysts spot hidden segments.
- Generation produces synthetic data that follow learned patterns, useful when real examples are scarce.
-
AI models based on learning type
Task-based models focus on the output, whereas learning styles describe the route a system takes to improve. The best training option depends on factors like the volume of labelled examples, how much the environment shifts over time, and whether the system must explore new actions.
- Supervised learning studies labelled examples and links inputs to known outcomes.
- Unsupervised learning scans unlabeled data to uncover arrangements that were not visible at first glance.
- Semi-supervised learning combines a small labeled set with a larger unlabeled set to improve model accuracy and performance.
- Reinforcement learning improves its choices by receiving feedback after each action and adjusting accordingly.
- Self-supervised and few-shot learning relies on either unlabeled material or a handful of labelled examples to craft reliable internal representations in a short time.
AI model architectures
These architectures power many production systems across vision, language and data-generation tasks. Each one introduces a distinct processing approach, making it simpler to align technical capabilities with specific business goals.
-
Deep neural networks
These networks process data through several connected layers, allowing them to learn complex patterns from images, sequences and signals.
- Convolutional Neural Network (CNN) analyses visual data by scanning for local features, making it the standard choice for image inspection.
- Recurrent Neural Network (RNN) reads information in order, which helps when the context depends on sequence, such as time-stamped transactions.
- Long Short-Term Memory (LSTM) extends the RNN design so it can keep important details over longer intervals, improving tasks like speech transcription.
-
Transformer models
Transformers focus on relationships among all parts of the input at once, which leads to strong results in understanding and producing language.
- BERT studies text in both directions to grasp context, supporting accurate sentiment or intent analysis.
- GPT predicts the next word in a sequence, enabling the creation of fluent summaries, answers and drafts.
- Large Language Model Meta AI (LLaMA) provides an open research foundation that teams can refine with domain-specific text.
-
Generative models
Generative models learn the structure of data well enough to produce new, realistic examples for design, simulation or augmentation.
- Generative Adversarial Network (GAN) trains two networks in competition, resulting in images that can fill gaps where real photos are scarce.
- Variational Autoencoder (VAE) compresses information into a smaller form and rebuilds it, which is useful for anomaly detection and data exploration.
- Diffusion model starts with random noise and iteratively improves it, yielding detailed visuals that support rapid concept work.
Since early 2024, the share of organizations regularly using generative AI climbed from 65 percent to 71 percent. – McKinsey
Specialized AI model variants
Some projects require architectures optimized for resource constraints, data formats or routing needs. These specialized families meet those requirements without sacrificing performance.
By size
The models listed here can run on both large cloud servers and compact edge devices.
- Large Language Models (LLMs) are trained on broad knowledge domains and can perform complex reasoning tasks at data center scale.
- Small Language Model (SLM) delivers key language functions in a footprint small enough for local deployment.
By objective
These models refine language handling through focused training goals such as filling gaps or compressing content.
- Masked Language Model (MLM) learns to predict missing words, which sharpens its grasp of context.
- Language Compression Model (LCM) condenses lengthy passages into concise form while retaining essential meaning.
- Language Action Model (LAM) converts plain instructions into structured steps that downstream systems can execute.
By modality
Multimodal architectures integrate visual and textual cues to improve understanding across data types.
- Vision-Language Model (VLM) links images with descriptive text, enabling accurate captioning and cross-modal search.
- Segment Anything Model (SAM) outlines objects within an image after a single prompt, streamlining labelling and editing.
By structure
These designs manage workloads by distributing inputs to specialized sub-models.
- Mixture of Experts (MoE) selects the most suitable expert model for each input, reducing computation without sacrificing accuracy.
How do you build and train AI models?
A disciplined process keeps AI work on schedule and within budget. The seven steps below outline a path from first idea to steady operation.
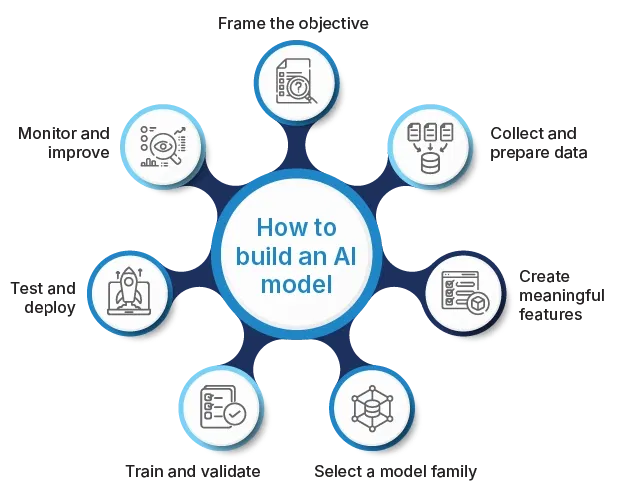
-
Frame the objective
Begin by stating the business question clearly and deciding how success will be measured.
-
Collect and prepare data
Work with data engineers to gather raw records, remove errors, handle missing values and organize the result into a structured format.
-
Create meaningful features
Transform raw fields into inputs the model can learn from, such as ratios, trends or encoded text. Good features can be more important than the choice of algorithm.
-
Select a model family
Review the data format and the task, then choose a model type that fits both. A decision tree handles structured tables, a convolutional network excels with images, and a transformer is suited to long text. Factor in the time and hardware budget before making the final selection.
-
Train and validate
Divide the cleaned data into two portions. Use the larger portion to teach the model, adjusting its settings until the error rate is acceptable. Run the smaller portion afterward to confirm that the learning carries over to records the model has not seen.
-
Test and deploy
Run a final check with a reserved sample to confirm performance. If the results meet the target, package the model in a service or batch job and place it in the live environment that supports the workflow.
-
Monitor and improve
Track accuracy, latency and drift in live traffic. When performance declines or data patterns change, collect new samples and repeat the training cycle.
Implementation insight
Begin with a modest proof of concept that runs on a limited sample. Early results highlight data quality gaps and guide goal refinement for full deployment. An experienced data science consultant can guide this stage, assess data readiness, and design a path from the pilot to a stable production system.
What is data bias in AI models?
Data bias is rooted in the data chosen for training. If the data set reflects only a part of reality, the system learns patterns that will favor the data subset and overlook others. Uneven sampling, gaps in historical records, or measurement errors are the usual causes of data bias, rather than faults in the learning method. The challenge is manageable with a disciplined approach. Careful data policies, regular reviews, and broader data sources move the model toward balanced performance for all users.
Quick wins for bias reduction
- Compare training data to current user demographics and add missing groups
- Apply random sampling when collecting new records to avoid over-representation.
- Use separate validation sets for each key subgroup and track accuracy across them.
- Review feature choices to remove fields that encode sensitive attributes.
- Schedule periodic bias and performance audits and retrain when performance drifts.
How to maintain data privacy in AI and ML models
Securing personal data builds trust and supports reliable AI results. The guidelines below outline practical measures that secure data at every stage of the project while keeping day-to-day work efficient and auditable.
- Always encrypt data while it is moving and while it is stored. Relying only on network barriers leaves information exposed when those barriers fail.
- Grant access through clearly defined roles and keep a complete audit log. Open file sharing or informal exchanges weaken accountability and add unnecessary risk.
- Remove personal identifiers before training. Use anonymization or tokenization. If data is merged without anonymization, privacy can be compromised.
- Store information only for the period set in the project charter. Schedule automatic removal when that period ends. Keeping data longer than necessary increases breach risk and complicates audits.
- Monitor data pipelines continuously. Test security controls on a regular schedule. Assuming past security measures will remain effective invites silent vulnerabilities.
- Map the data flows from intake to output. Record how user consent is collected and applied. Treating privacy documentation as an afterthought makes it difficult to demonstrate compliance when questions arise.
Use cases of AI models
Concrete examples help leaders see how a thoughtful match between data and technique can solve pressing problems. The use cases below cover several sectors and show how a suitable model, applied to the right task, produces measurable gains.
-
Industry: Semiconductor
- Task: Quality engineers review detailed wafer photographs and must find microscopic surface flaws before the lithography stage begins.
- Model: A convolutional neural network processes visual data through layered filters. These filters detect subtle texture changes that indicate early process drift.
- Impact: Immediate alerts on each lot allow process engineers to fine-tune equipment settings early in the run, keeping yield on target.
-
Industry: Finance
- Task: The fraud team screens every card transaction in real time and must decide whether to approve or hold the payment.
- Model: A gradient-boosted decision tree uncovers subtle patterns in the transaction data while still returning a risk score within the required millisecond window.
- Impact: Reviewers now focus on a much smaller queue of uncertain cases, and genuine customers see fewer interruptions at checkout.
-
Industry: Healthcare
- Task: Radiologists need accurate outlines of tumors on MRI images to plan radiation dosage and protect healthy tissue.
- Model: The U-Net architecture pairs fine localization with broader context, producing clear boundary maps that match clinical workflow.
- Impact: Automated contours shorten the manual drawing step, giving specialists more time to adjust treatment plans for each patient.
Between 2013 and 2023, the global install base of industrial robots roughly tripled, reaching 541,000 units in 2023
Source: Stanford HAI’s 2025 AI index report -
Industry: Retail
- Task: Merchandising teams forecast weekly demand for seasonal goods across several regions so they can set purchase orders.
- Model: A long short-term memory network learns both historic sales patterns and calendar effects, improving on simpler curve-fit methods.
- Impact: Order volumes align more closely with true demand, which trims storage costs and reduces markdowns at the end of the season.
-
Industry: Logistics
- Task: Dispatch managers want to choose daily delivery routes that adapt to traffic and customer time windows.
- Model: A reinforcement learning agent improves route selection by learning from driver feedback and live road data.
- Impact: Vehicles travel fewer miles per drop, and arrival times stay within promised windows even on busy days.
-
Industry: Telecom
- Task: Operations groups need early warning when network hardware is likely to fail.
- Model: A random forest processes sensor readings and operating conditions, issuing forecasts that rank components by risk.
- Impact: Maintenance teams switch from emergency repairs to planned visits, keeping call quality steady and lowering overtime. These scenarios show that when data quality, problem framing and model choice align, artificial intelligence moves quickly from concept to operational gain.
Realize measurable gains with a clear AI roadmap
Many companies see the potential of advanced AI models but are unsure where to start or how to move beyond small trials. When business goals, data readiness, model design, and governance align, adoption moves faster. A coordinated framework can guide you through every phase of your AI initiative. An AI consulting service provider can help align business goals with the right data pipelines and model architectures, embed privacy and fairness checkpoints, and deliver a deployment plan that fits your schedule and budget.
FAQs
1. What are the tools and frameworks used to build AI models?
Popular frameworks for model development include TensorFlow, PyTorch, scikit-learn and Keras. Data processing often involves pandas, NumPy and Apache Spark
2. Which AI model is best for text generation?
Transformer-based models like GPT (Generative Pretrained Transformer) and Llama excel at text generation because they learn patterns across large text corpora and predict coherent continuations.
3. What is the difference between LLM and SLM?
An LLM (Large Language Model) contains billions of parameters for deep understanding and generation of language at scale. An SLM (Small Language Model) uses fewer parameters for simpler tasks and can run locally on edge devices with limited compute.
4. How is a generative AI model different from a predictive model?
Generative AI models learn the patterns in their training data and then produce new content such as text or images. Predictive models analyze input features to forecast outcomes or assign categories.
5. What are some examples of open-source AI models?
Popular open-source models include BERT and RoBERTa for language understanding, YOLO for real-time object detection, and Stable Diffusion for image generation.
6. How do you choose the right AI model for your business?
Match the model’s strengths to your use case by considering the data type, performance requirements, and available infrastructure. Pilot multiple architectures on a representative dataset to compare accuracy and resource needs.
7. Can I train my own AI model? If yes, how?
Yes. You can prepare a labeled dataset, select an appropriate framework (such as TensorFlow or PyTorch), and follow a training pipeline of data cleaning, feature preparation, model selection, training, and evaluation. Engaging an experienced AI specialist can streamline these steps and ensure each phase follows industry best practices. Get in touch with us to deliver a complete, end-to-end solution from data preparation through model deployment.
8. What are the challenges in building an AI model?
Common challenges include gathering sufficient high-quality data, preventing overfitting, ensuring unbiased results, and integrating the model into existing systems.
9. Are AI models always accurate?
No. Model accuracy depends on the quality and representativeness of training data, the appropriateness of the chosen architecture, and ongoing monitoring. Even well-trained models require regular validation to maintain performance.
10. What is the difference between supervised and unsupervised models?
Supervised models learn from labeled data where each example has a known output. Unsupervised models find patterns or groupings in unlabeled data without predefined targets.