How Softweb helped a global manufacturing enterprise achieve 79% greater data visibility with Databricks
Our client is a global manufacturing enterprise producing high-precision industrial components across automotive, aerospace, and medical sectors. Fragmented data pipelines, growing data volumes, and limited reporting visibility made it difficult for their teams to access timely operational insights. Softweb modernized their analytics environment with Databricks, delivering 64% faster processing, and 11% revenue growth.
 Industry: Manufacturing
Industry: Manufacturing  Business type: Enterprise
Business type: Enterprise - Services: Databricks implementation, Analytics modernization
- Technology: Azure Databricks, Microsoft Power BI, Python, SQL
Client profile
The company operates in the manufacturing sector, producing high-precision industrial components used across automotive, aerospace, and medical applications. With decades of industry experience and a diverse product portfolio, the enterprise supports large-scale manufacturing and distribution operations across multiple regions.
A broad ecosystem of manufacturing facilities, suppliers, and regional operations supports the company’s production and distribution activities across global markets. The company’s components reach end markets across multiple continents, supporting some of the most specification-driven and quality-critical applications within global industrial manufacturing.
Technical challenges
The client managed large volumes of operational, supply chain, and reporting data across multiple enterprise systems and regional business functions. Existing processing and reporting environments supported day-to-day operations but created growing complexity around data accessibility, large-scale processing, and operational visibility across the organization.
Growing data volumes
Managing growing volumes of operational and supply chain data across systems created complexity in storage, accessibility, and processing workflows.
Complex data pipelines
Extracting, transforming, and managing data across multiple systems required time-consuming workflows and increased processing overhead.
Performance bottlenecks
Existing platforms struggled to scale efficiently with increasing workloads, leading to processing delays and operational bottlenecks.
Limited operational visibility
Slow processing and fragmented reporting environments made it difficult for teams to access timely insights for operational decision-making.
Our solution
We modernized the client’s analytics and data processing environment using Databricks, aligning the implementation with their large-scale reporting, integration, and operational data requirements. Through this modernization approach, structured and operational data pipelines were unified within a scalable architecture built around reporting, analytics, and cross-functional data access across business operations.
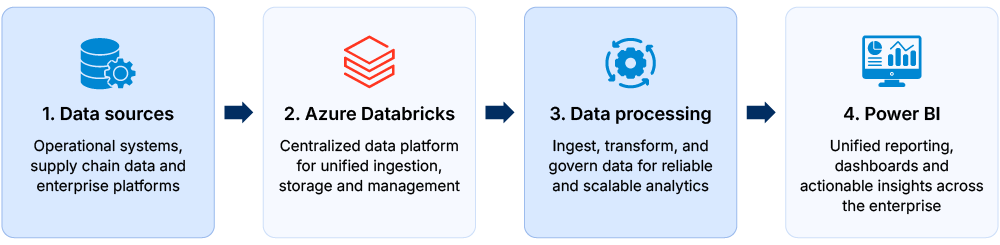
To support this architecture, layered data pipelines, centralized transformation workflows, and elastic compute resources were implemented for large-scale data processing and pipeline management. Processing and reporting workflows were further integrated with enterprise data activities, covering centralized analytics operations, regional data accessibility, and large-scale reporting requirements across business systems.
Unified data foundation for centralized processing
We consolidated structured and operational data workflows into a centralized Databricks environment designed for enterprise-scale processing, reporting, and analytics activities. Within this environment, data from operational systems, supply chain workflows, and enterprise platforms was brought into a shared processing framework. The framework was aligned with enterprise reporting and data management requirements.
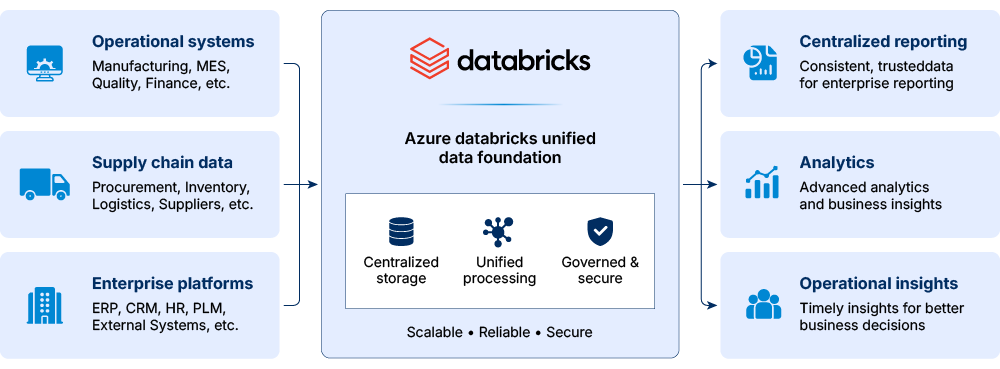
Structured and unstructured data workflows were brought together through unified ingestion and processing pipelines connected across operational and reporting systems. These pipelines were structured to route data movement, coordinate processing activities, and maintain consistency across enterprise and operational systems.
Layered data architecture for scalable processing
A structured medallion architecture was implemented within the Databricks environment using staged data ingestion, transformation, and reporting layers to support scalable data processing and centralized reporting workflows.
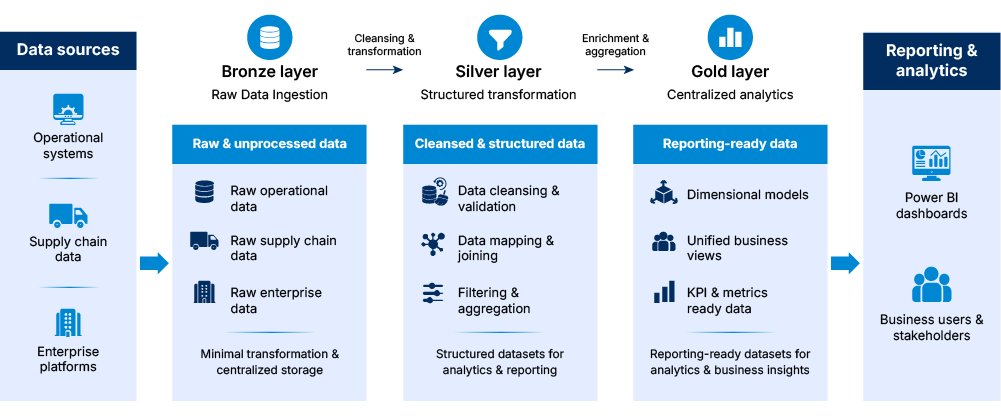
- Bronze layer: Raw data ingestion
- Silver layer: Structured transformation
- Gold layer: Centralized analytics
Raw operational, supply chain, and enterprise data was ingested into the Bronze layer with minimal transformation to support centralized storage and controlled pipeline processing.
The Silver layer supported data mapping, filtering, joining, and transformation workflows to prepare structured datasets for downstream analytics and reporting activities.
Reporting-ready datasets, dimensional models, and unified business views were organized within the Gold layer to support centralized analytics and operational reporting workflows.
Streamlined data transformation and workflow management
We streamlined data transformation workflows to simplify large-scale processing and organize reporting pipelines within a centralized framework. Building on this framework, data mapping, transformation, and orchestration activities were consolidated into unified workflows aligned with enterprise reporting and analytics operations.
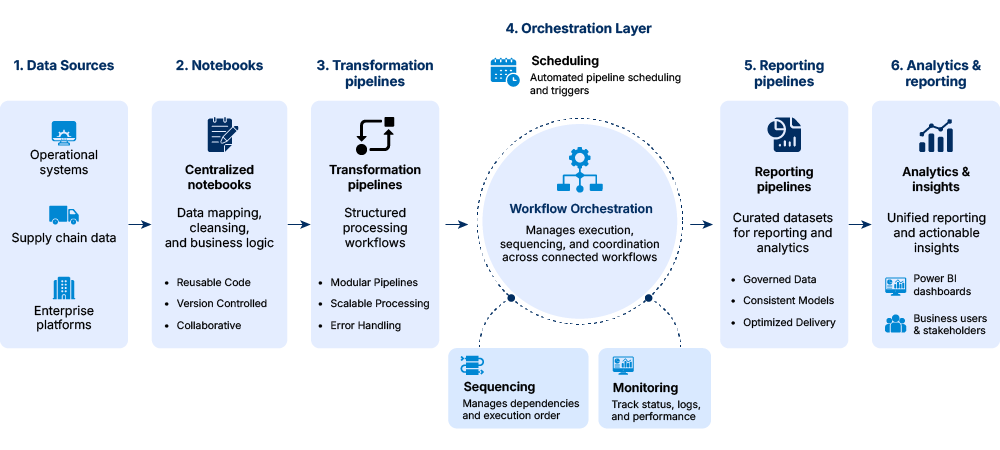
Centralized notebooks and processing pipelines organized complex transformation workflows connected across enterprise and operational data systems. Orchestration layers within the environment handled data movement sequencing, pipeline scheduling, and processing coordination across connected workflows.
Elastic compute environment for scalable workloads
We implemented an elastic compute environment within Databricks to support large-scale processing workloads across reporting, analytics, and transformation activities. Compute clusters were configured to scale processing resources based on workload requirements while maintaining standardized configurations across operational workflows.
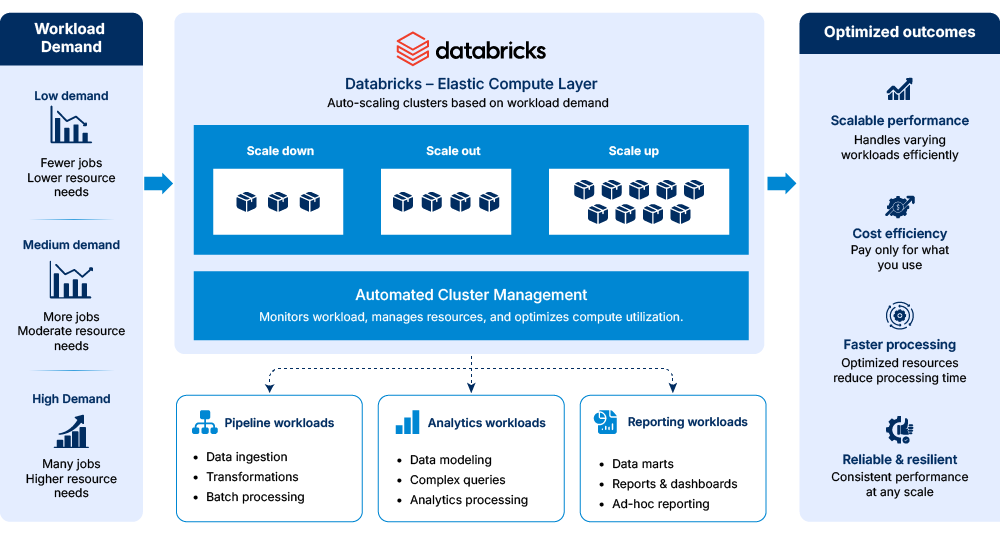
Processing environments were structured to distribute workloads across pipeline, analytics, and reporting activities based on active demand. Automated cluster management governed compute utilization to match active processing requirements across the centralized analytics environment.
Cross-region data accessibility and governance
We configured the Databricks environment for cross-region data accessibility across reporting, analytics, and operational workflows within the enterprise ecosystem. Shared data access structures were implemented, enabling controlled data availability across regional operations, business functions, and connected reporting environments.
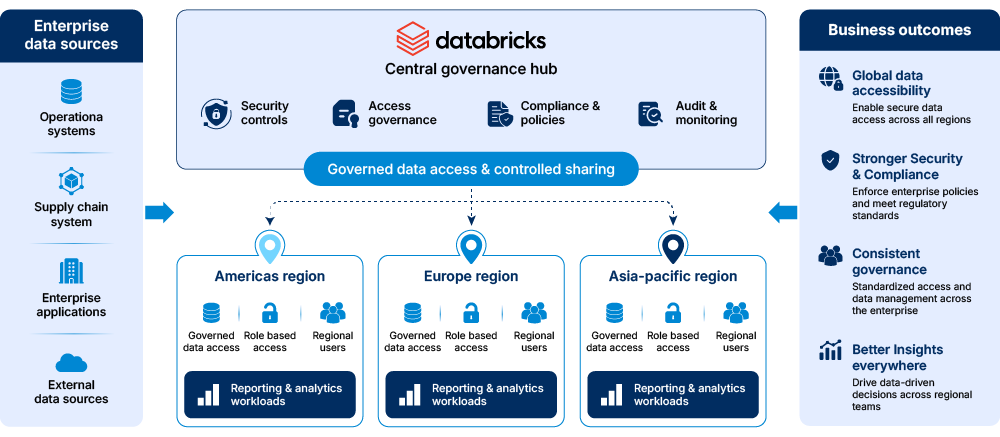
Governance workflows were mapped to data processing and reporting activities across operational systems and regional business functions. Enterprise-grade security controls and access governance frameworks were established, meeting data management and compliance requirements across regional operations.
Operational reporting and analytics integration
We integrated reporting and analytics workflows within the Databricks environment to centralize operational reporting across business and regional systems. Through these integrated workflows, analytics pipelines and processed datasets were connected with operational data activities across supply chain, logistics, procurement, and enterprise operations.
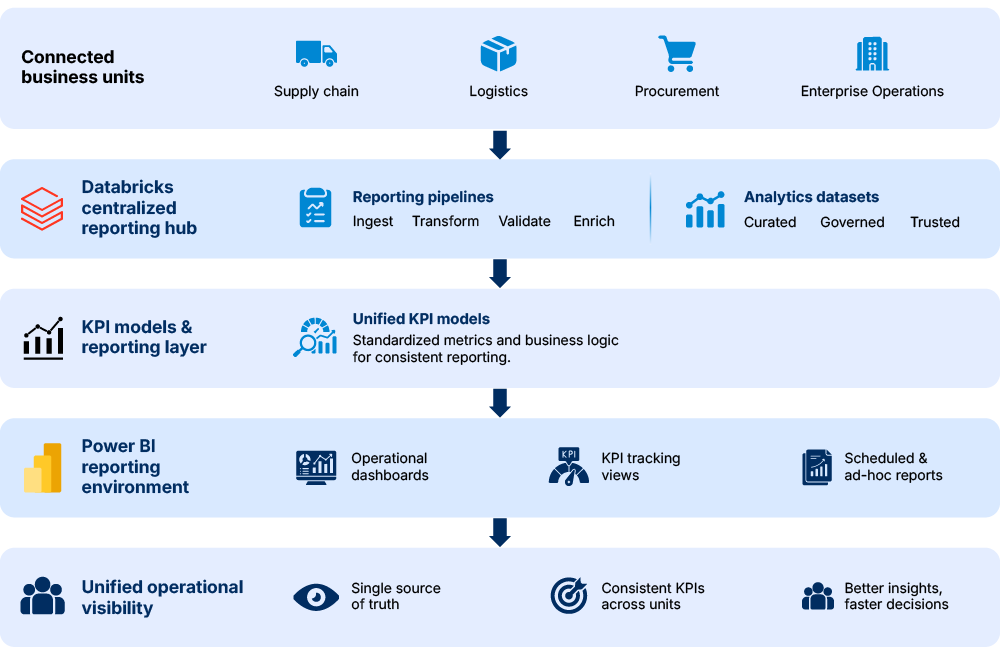
Power BI environments were connected to centralized reporting pipelines and analytics datasets across the broader enterprise data ecosystem. KPI models, operational dashboards, and reporting workflows were established to unify analytics activities across business units and operational environments.
Business goals and measurable outcomes
| Business objective | Business benefit delivered |
|---|---|
| Improve operational visibility | 79% increase in data visibility across reporting and operational workflows through centralized analytics integration |
| Accelerate data processing | 64% reduction in processing time through streamlined transformation workflows and centralized processing pipelines |
| Support measurable business growth | 11% revenue growth supported by centralized analytics access and operational reporting workflows |
| Centralize reporting workflows | Unified reporting pipelines centralized operational and regional reporting activities across business systems |
| Reduce data management complexity | Centralized ingestion and transformation workflows simplified large-scale data processing activities |
| Enable cross-region data access | Governed access structures supported controlled reporting and analytics access across regional operations |
Tech stack
- Data Platform
- Azure Databricks, Delta Lake, Medallion Architecture (Bronze, Silver, Gold Layers)
- Programming & Query Languages
- Python, SQL
- Analytics & Reporting
- Microsoft Power BI, KPI Dashboards, Operational Analytics
- Data Engineering
- Data Ingestion Pipelines, ETL/ELT Workflows, Data Transformation
- Workflow & Processing
- Databricks Notebooks, Pipeline Orchestration, Automated Data Workflows
- Compute & Scalability
- Databricks Elastic Compute, Scalable Data Processing Clusters
- Data Governance
- Cross-Region Data Access, Security Controls, Data Management Frameworks
- Architecture
- Enterprise Data Lakehouse Architecture for Manufacturing Analytics & Reporting
Similar case studies

Automating SAP Invoice Management with Power Automate Desktop
Transforming equipment calibration: A mobile app solution for enhanced efficiency
Generative AI solution improved hardware schematics and reduced time-to-market by 42%
Connect Now
Our experts would be eager to hear you.
