Between product concept and production line, development cycles carry a cost that accumulates with every delay. The planning, execution, and data systems that manufacturers built over decades were well-suited to the pace of their time, when multi-year product cycles were standard and release frequency was not yet a competitive differentiator. The pace has changed significantly. Many of the systems have not.
92% of manufacturers identify smart manufacturing as their primary competitive driver over the next three years. Fewer than one in five say they have the foundations ready to act on it.
– Deloitte, 2025 Smart Manufacturing Survey
The finding points to something precise: not a shortage of ambition, and not a shortage of investment. An architecture that was built for a pace the market has moved past.
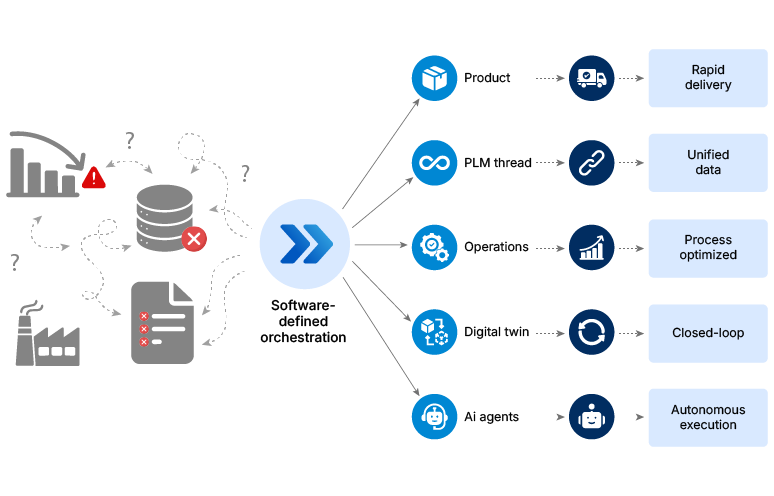
Five connected shifts are rewriting how manufacturers close that gap. From how products are first defined to how plants make decisions in real time, each shift builds on the one before it. Together, they form the sequence that turns a transformation roadmap into a working system. This article traces each of those five shifts in sequence, from product design through the cost structures that determine whether everything built on top of it can scale.
Stage 1: Designing for speed
For most of manufacturing’s modern history, a product’s capabilities were decided the moment its hardware was finalized. Updating those capabilities meant restarting a development cycle that already ran long. The competitive pressure to release faster kept growing. The design process did not.
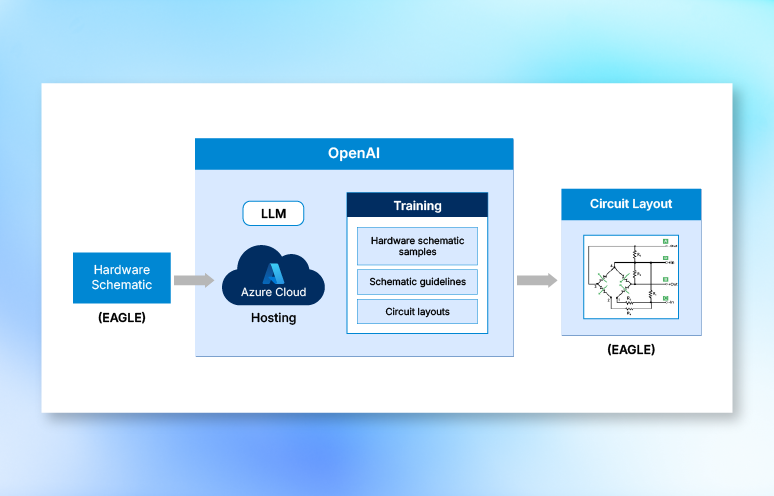
Software-defined product architecture changes the starting point.
The hardware-first design assumption is slowing release cycles
When a product is designed around fixed hardware, every feature decision carries a physical consequence. A new capability means a new component. A new component means requalification, retooling, and a longer cycle before anything reaches the market.
The cost of that model is not just time. It is the ability to respond. When a hardware-locked product finally reaches production, the market requirement that shaped it has often already changed.
Decoupling software from hardware changes what design teams can do
Software-defined architecture separates the two at the design stage itself. Software is built to run on high-performance edge devices independently of the hardware beneath it. Features are designed as software modules rather than physical configurations. Updates can be validated and released continuously, without triggering a full hardware requalification cycle.
The design process shifts from “what hardware do we need” to “what software platform do we build on.” That shift compresses cycles because iteration no longer requires physical retooling.
What manufacturers who made this shift are seeing
Two renowned manufacturers rebuilt their product architecture from the design stage up. What changed was not just their timelines. When product capability stopped being tied directly to hardware configuration, the pace at which products could respond to market requirements changed considerably.
These results share a common starting point: a design decision made before production was involved. Faster products, however, create a new kind of pressure. The data that defines them now needs to travel just as quickly, across R&D, compliance, and the plant floor. That is exactly where the next stage begins.

Stage 2: Connecting the data
A product can be designed precisely and still arrive at the production line with critical information missing. Across most manufacturing environments, the data describing that product passes through several disconnected systems before it reaches the people who need to act on it. At each handoff, the risk of something being outdated, incomplete, or simply lost increases.
By the time that data arrived, something was outdated, something was missing, and someone had to proceed without the full picture. That happens not occasionally but at every handoff where systems do not communicate: between the lab and regulatory, between regulatory and manufacturing, between manufacturing and the supplier.
The gap between what was designed and what production actually knows is not a data management problem. It is a structural one. When product information is fragmented across disconnected systems, every handoff adds delay back into the release cycle.
Why product data gets lost between the lab and the plant floor
When product information lives across separate R&D, regulatory, and manufacturing systems that were never built to communicate with each other, gaps are inevitable. A formulation change logged in the lab does not automatically update the compliance record. A regulatory submission requires someone to manually reconcile three different databases.
A production team adjusts a process parameter with no way of knowing whether that change affects a regulatory certification in progress elsewhere. The production floor system and the compliance system were never connected, so changes in one do not register in the other. The gap only becomes visible when something goes wrong.
Each system is doing its job correctly. The problem lives in the space between them, and it compounds at every transition point across the product lifecycle.
What a digital thread actually fixes
A PLM-based digital thread creates a connected, traceable flow of product information from initial concept through regulatory submission and into manufacturing execution. Rather than product data living in separate systems that sync imperfectly, a digital thread maintains one accessible record that all functions draw from.
The practical impact is direct. Organizations with a connected digital thread access critical product information 80 to 90% faster than those working across fragmented environments. That speed difference is not just an efficiency gain. It is the difference between catching a compliance issue before production starts and discovering it after.
The PLM software market reflects how broadly manufacturers are already investing in this infrastructure. At approximately $50 billion in 2026 and growing at over 8% annually, with cloud-based deployments expanding at nearly 11%, this is not a category in early adoption. Among the world’s 500 largest manufacturers, 72% have already integrated PLM solutions into their operations.
What organizations running a digital thread are seeing
Three process manufacturers, three different structural problems. One underlying fix: connecting product data so it moves with the product, not behind it.
A digital thread does not replace the systems that already exist across design, compliance, and manufacturing. It connects them, so product information no longer has to be chased, reconciled, or recreated at each handoff. A connected data layer also creates the foundation the next stage requires: an operation that can act on what it knows in real time, not just report it.
Stage 3: Closing the loop
Most manufacturing organizations running digital twin programs have built something genuinely useful. They can monitor asset performance, simulate production scenarios, and visualize what is happening across a facility in near real time.
The challenge is what happens after that. Delays between insight and response slow production adjustments and issue resolution, and those delays compound into how quickly products can reach and adapt to the market.
An insight surfaces. A recommendation appears on a dashboard. Someone reviews it, decides what to do, and initiates a response, if the shift schedule allows for it. The loop between insight and action runs through a human decision point, and that decision point is increasingly the rate-limiting factor in operations built to move faster.
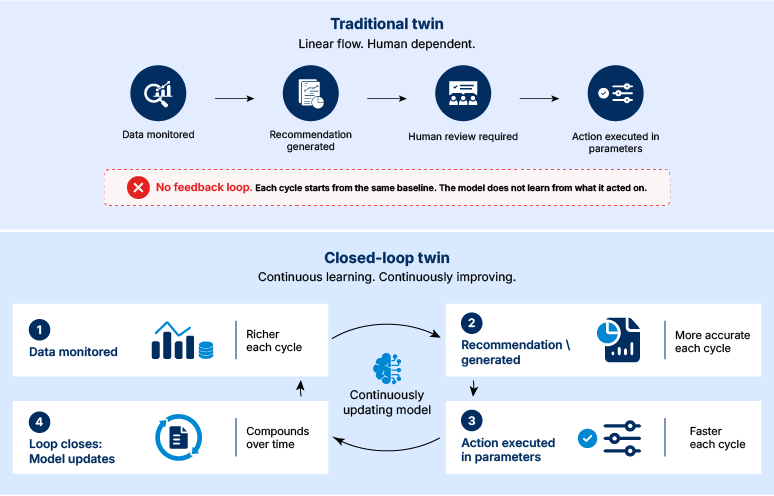
What separates a monitoring twin from a closed-loop one
Traditional digital twins are built to observe. They ingest data, generate models, and present the resulting picture to the people responsible for acting on it. The value is real: visibility into asset behavior and production performance that did not exist before.
A closed-loop digital twin goes further. Rather than generating a recommendation for a human to act on, it takes the action directly, within defined parameters, and updates its own model based on what the response produces. The twin ingests real-time operational data, optimizes against defined objectives, executes changes to schedules or equipment settings, and closes the feedback loop without waiting for a review cycle.
Closing that gap is fundamentally an integration challenge, not a technology procurement decision. Most manufacturing facilities built their IT and OT environments independently, on different protocols, with no shared data layer between them. Bridging that gap is where most closed-loop implementations either succeed or stall, and it is a decision that has to be made before the twin is deployed, not after.
What organizations that closed the loop are seeing
The results from early closed-loop implementations are specific, not directional. Three organizations, three different operational contexts, one consistent finding: when the twin acts instead of advising, the numbers change.
Across all three cases, the deciding factor was a pre-built integration layer that allowed existing operational data to drive decisions in real time. Production systems that can respond without waiting for review cycles maintain throughput, reduce downtime, and keep product delivery on schedule. That same integration layer is what the next stage builds on, where the question shifts from whether a system can act, to whether it can learn from what it acts on and make better decisions over time.
Stage 4: Deploying intelligence
The role of AI in most manufacturing operations today remains largely advisory. It detects anomalies, generates reports, and presents options for human review. From there, an operator evaluates the output and determines the response.
That model is changing because the volume and speed of decisions on a modern production floor has outpaced what human review cycles can reliably handle. AI agents are designed to handle high-frequency, time-sensitive decisions in quality, maintenance, and scheduling. These are precisely the categories where human review cycles create the most measurable operational delay. When a scheduling system needs to respond to a line disruption in minutes, waiting for a supervisor to read a dashboard and initiate a response is itself a source of operational loss.
Semiautonomous AI agents address that gap by moving from recommendation to orchestration, within defined boundaries, with humans retaining approval at critical decision points.
Where AI agents are operating today
The current baseline is approximately 2% of key production operations, quality processes, and maintenance use cases being orchestrated by AI agents. The trajectory points to 10% by 2030. Deloitte projects agentic AI adoption in manufacturing will grow fourfold by 2026, from 6% to 24% of organizations deploying it at meaningful scale.
The shift is not uniform across the industry. Early adopters are concentrating agent deployment in the areas where decision volume is highest and human review cycles create measurable delay: quality inspection, predictive maintenance triggering, and production scheduling adjustments. Across all three, the defining characteristic is frequency, not complexity. These decisions accumulate faster than any review cycle can reliably absorb.
What organizations deploying agents are seeing
Three manufacturers were each facing a distinct operational problem. Each applied the same underlying principle: deploy agents to handle the high-frequency decisions that had been consuming operator time without requiring operator-level judgment.
Data infrastructure built to support agent deployment before the agents went live was the differentiating factor across each of these results, not model sophistication or retrofitting once problems emerged.
The governance requirement that most deployments skip
Through 2027, the majority of AI projects across industries are expected to fall short of their objectives due to inadequate data governance. Manufacturing is not exempt from that pattern. An agent operating on incomplete, inconsistent, or poorly governed data does not fail visibly. It makes plausible-looking decisions that quietly compound operational problems.
Human-in-the-loop design is the architecture requirement that makes agent deployment safe to scale. Organizations that treat it as a foundational design decision, rather than a late-stage addition, are the ones sustaining agent programs beyond the pilot phase. In practice, that means defining agency levels clearly, monitoring model behavior on an ongoing basis, and aligning with OT safety standards before the first agent goes live.
Deloitte projects manufacturing organizations deploying agentic AI at meaningful scale to grow from 6% to 24% within the next phase of industrial AI adoption. Building the data plane and governance layer that makes that safe is the preparation most transformation roadmaps currently skip.
Stage 5: Managing the cost
Manufacturers building toward the architecture described in the previous four stages are going to encounter a cost structure that looks different from what current budgets reflect.
Enterprise software pricing has shifted from predictable, fixed-rate models toward consumption-based structures tied to usage, compute, and the number of machine users operating within a system. Most procurement frameworks were designed around the former.
Why this cost increase is structural, not negotiable
Three forces are converging to push manufacturing software costs up by an estimated 40% by 2029. None of them is new, but together they create a compounding pressure that most current budgets were not built to absorb.
Inflation continues to drive IT costs up by 5 to 7% annually across hardware, software, and services. The growing adoption of AI within manufacturing systems adds a second layer, increasing reliance on subscription-based cloud platforms where licensing scales with usage rather than sitting at a fixed annual rate.
The third force is the least understood, and the most significant for manufacturers building agent-heavy operations. When an AI agent calls an API, consumes compute, or processes data, it incurs fees in exactly the same way a human user does. Machine users are becoming a billable category in enterprise software agreements, and most contracts currently in place were negotiated before that category existed.
Four things to do before the contracts are signed
Managing this cost exposure comes down to one decision: whether the organization modeled machine-user consumption before deploying agents, or discovered the exposure after vendor contracts were already in place.
Four actions worth building into procurement practice now: audit current licensing structures to identify where machine-user consumption is unaccounted for; define clear and unambiguous usage metrics before any vendor negotiation begins; and build spending caps and burst allowances into master license agreements before scale commits the organization to a fixed cost structure.
The fourth action is the one most organizations skip: securing volume discounts alongside flexible tier-switching rights before deployment creates vendor dependency. The time to model this is before the agents are running, not after the invoice arrives.
Every manufacturer in this article started where you are. The difference was where they built first.
The five stages in this article are not a checklist. They are a system. Software-defined products generate the data that digital threads connect. Digital threads feed the twins. The twins inform the agents. Agents drive decisions, and all of it runs on a software cost structure that is changing in real time.
Taking any one stage out of that sequence makes the stages that follow harder to sustain. A closed-loop twin running on fragmented, unthreaded product data optimizes against incomplete information. An AI agent operating on infrastructure that was never designed for agents reaches governance limits before it reaches scale.
The manufacturers closing the gap between ambition and readiness have moved past the pilot phase. They are identifying which stage in the sequence has the weakest foundation and building from there. The World Economic Forum’s research across its Global Lighthouse Network is consistent on this point: 75% of top-performing sites made data readiness a prerequisite before scaling any AI deployment, not a parallel workstream.
Of the five stages covered here, which one describes where your architecture currently stops? The answer to that question is a more useful starting point than any roadmap that assumes all five are equally ready to build.