LLMOps services
Stabilize model pipelines and reduce failure points with LLMOps solutions that track, govern, and refine every stage of the model lifecycle.
Talk to our expertsStabilize model pipelines and reduce failure points with LLMOps solutions that track, govern, and refine every stage of the model lifecycle.
Talk to our expertsOur Clients

In most organizations, AI models work perfectly in development but fail in the production phase. Debugging becomes slow because there is no visibility into why a model changed, what data shifted, or which update triggered failure. Our team implements end-to-end LLMOps solutions that give you complete control over your model lifecycle. We set up training workflows, version tracking, safe rollout paths, automated testing, and round-the-clock monitoring. Our team uses advanced tools to accelerate deployment and model fine-tuning to meet tight project timelines. We specialize in building robust LLMOps infrastructure using proven technologies like distributed computing, GPU optimization, and automated monitoring systems. You get LLM systems built for production that integrate seamlessly with your stack, enforce data governance, and scale reliably across enterprise workloads. Moreover, your team receives support from us at every stage to turn your ideas into high-performing, production-ready solutions.

We guide you through every stage of LLM operations by reviewing your systems, mapping gaps in model performance and infrastructure stability, and designing a practical roadmap. Our team creates tailored strategies using LLMops for deployment, scaling, and optimization that match your business requirements. We help you make an informed decision to reduce costs and build AI that delivers real results.

We implement structured monitoring and organized versioning, that enables your team to understand what’s really happening inside your LLMs. Our systems log every response, track version changes, and send automated alerts when issues appear. Thus, your team gains transparency into model behavior, debugging becomes faster, and you can continuously improve your AI model.

We design, test, and refine prompts with clear rules, ensuring your models function efficiently with evolving data and business needs. Our team builds and maintains prompts using the latest LLMOps frameworks and structured version control. We help your business improve response quality and maintain performance without constant rework.

We connect your AI models with backend systems, pipelines, and data storage to create a unified system. Our team integrates your backend system through the MCP client-server and custom pipelines. We enhance your AI performance, helping your business run applications more efficiently across multiple environments.

We automate your entire model lifecycle with CI/CD pipelines built for LLMs. Our team automates deployment, rollback, and updates implementing CI/CD. We ensure your model stays production-ready, enabling your business to push updates faster, enhancing performance.

We fine-tune your LLM base using your internal data to align it with your processes and organizational goals. Our team enhances your model performance by fine-tuning rules and enhancing computational efficiency. As a result, you can reduce operational costs and deliver faster results.

We create multi-agent systems that function under your real business use case. Our team implements multi-agent workflows by coordinating agent networks that share tasks, manage resources, and keep your system production ready.

We secure your LLM operations by establishing governance systems, centralizing monitoring, enforcing compliance policies, and tracking risks across your model portfolio. Our robust security protocols protect your sensitive data, meet regulatory requirements, and reduce operational risk across your entire AI portfolio.

We automate your entire LLMOps workflow to minimize costs. Our CI/CD automation streamlines testing, deployment, and fine-tuning processes. Automated workflows reduce manual overhead and help your business control model costs without slowing innovation.
We use real-time tracing and performance profiling to:
Moving from LLM to Ops shifts your AI from isolated experiments to a fully managed lifecycle. It creates a system where performance, cost, and governance move in sync, giving your teams a dependable model pipeline instead of unpredictable outcomes.
| Without LLMOps | With LLMOps |
|---|---|
| You're dealing with unpredictable outputs, watching your model's accuracy decline, and struggling with performance issues | You get real-time insights into your model’s health, catch drift before it impacts your users, and maintain consistent quality |
| Your team spends weeks on manual deployments, constantly resolving errors, and struggling to push updates to production | You deliver faster with automated pipelines, iterate confidently, and roll back instantly when something goes wrong |
| You face rising bills, losing money to inefficient usage | You optimize your token usage and forecast costs accurately |
| You lack visibility into compliance, can’t track issues, and fear data slipping out | You gain complete visibility, meet regulatory requirements effortlessly, and stay confident your data is protected |

Continuous model monitoring
Tracks model performance in real time that prevents errors at an early stage and ensures consistent accuracy
Automated model deployment
Deploys model across environments, reducing manual effort and accelerating rollout cycles
Data governance compliance
Enforces regulatory adherence with lineage tracking and governance rules, minimizing risk of violations and penalties
Version control management
Maintains multiple model versions, enabling safe rollback and experimentation
Performance analytics dashboard
Provides actionable insights into model outputs, usage, and accuracy trends, improving decision-making across AI platforms.
Resource optimization
Allocates compute and storage based on demand, reducing operational costs and ensuring high-performance operations at scale.
Security and access control
Protects sensitive data with role-based access, encryption, and activity monitoring while enhancing collaboration across organizations.
Lifecycle automation
Streamlines end-to-end model processes, accelerating deployment, and ensuring consistent operational standards.
We streamline AI deployment, accelerate updates, and ensure your models deliver faster, reliable results, helping your business act on insights immediately.
Deploy faster nowIndustry
Logistics and supply chain management
Technologies
Artificial intelligence (AI), large language models (LLMs), MySQL
Challenges
Business Impact

Industry
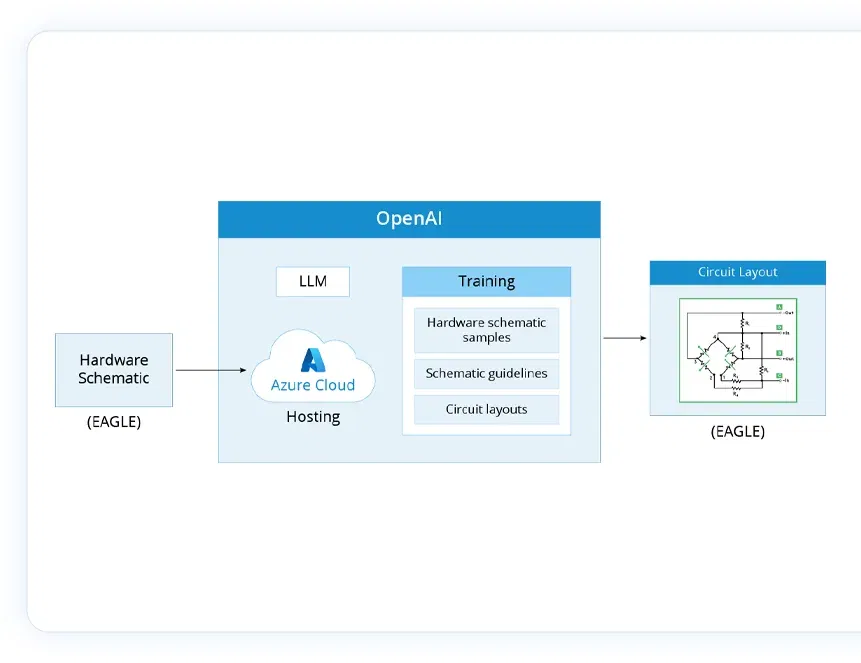
Manufacturing
Technologies
Python, LangChain, Azure Cloud, LLM
Challenges
Business impact
Client
A renowned original equipment manufacturer
Explore the results our solutions are delivering for businesses in every industry.
Softweb Solutions has been my go to software solutions provider for factory automation. As subject matter experts, they bring exceptional talent. But of greater value is their customer service and support. In short, they are thorough, detailed, knowledgeable and they deliver. Through all this, they develop trust and confidence that builds and sustains the foundation of a solid relationship.
Dean Harms
Regional Manager
Softweb Solutions provided the AI-driven platform we needed — one that not only streamlined our claim processing but also significantly enhanced our operational efficiency. I highly recommend Softweb Solutions to any organization seeking to modernize and streamline their processes with intelligent automation. They have truly helped us elevate our claims management to the next level.
Stan Kanterman
President
We guide you through every stage of the LLMOps journey, making the entire lifecycle easy to follow. Our approach removes guesswork and ensures your models transition smoothly from build, deploy to optimize.
We begin by mapping your current infrastructure, processes, data paths, and goals. It ensures that our LLMOps approach aligns perfectly with your organizational objectives and regulatory compliance. With this approach, we plan the LLMOps lifecycle that fits your business needs.
We assess your AI readiness across data quality, workflows, and governance. Our team identifies operational gaps and then designs a strategic roadmap using LLMOps that transforms fragmented processes into unified operations that improve efficiency and performance.
We design architecture tailored to your use cases, covering CI/CD pipelines, observability, governance, and security. Our design ensures your LLMOps environment integrates seamlessly with enterprise systems while maintaining compliance and operational excellence.
We optimize models from development to production through automated pipelines that validate, version, and test each release. Our team continuously monitors your models and fine-tunes them to make them ready for real-world business applications.
Once models go live, we track performance metrics, analyze failure patterns, and optimize execution paths for cost and accuracy. Our continuous optimizations include model retraining, infrastructure tuning, and efficiency improvements based on data.
We provide continuous technical support, scaling your LLMOps capabilities as demand grows. Our ongoing support ensures your LLMOps processes scale smoothly, remain resilient, and are ready for future expansion.
10+ years building scalable LLMOps infrastructures that manage model lifecycles, ensure uptime, and maintain compliance in enterprise environments
60+ specialists in LLMOps engineering, including CI/CD architects, observability experts, model registry managers, and deployment automation engineers
End-to-end LLMOps orchestration across Azure OpenAI, AWS Bedrock, and Google Gemini featuring automated deployments, version management, and cross-cloud observability
Production-grade LLMOps that operates high-volume chatbot systems, document intelligence workflows, vector search infrastructure, and personalization engines with SLA guarantees
Proven LLMOps accelerators for rapid deployment, continuous monitoring, automated retraining, and cost optimization, transforming AI investments into measurable business value
The purpose of LLMOps is to help you run large language models in a stable, predictable, and scalable way. It removes the guesswork from deployment, keeps models aligned with real-world data, and gives you full control over performance, cost, and compliance.
DevOps focuses on software delivery. LLMOps manage the entire lifecycle of language models from deployment, evaluation, drift detection, optimization, to governance. It handles the fluid nature of model behavior, which traditional DevOps workflows can’t fully support.
The best practices followed while implementing LLMOps are strong versioning, automated evaluation pipelines, continuous monitoring, strict access controls, reproducible experiments, cost tracking, and clear governance frameworks. These practices keep models reliable, compliant, and ready for real-world conditions.
Financial services, healthcare, retail, telecom, logistics, insurance, manufacturing, and public sector teams are moving fast. These sectors rely on accuracy, compliance, and high-volume decisioning—areas where LLMOps brings immediate value.
MLOps supports the lifecycle of traditional machine learning models. LLMOps is built specifically for generative and language models, which require tighter controls, constant evaluation, hallucination management, prompt governance, and cost oversight.
Customer service automation, content generation, fraud detection, quality checks, business querying, code assistance, research workflows, document processing, and decision-support systems. Any use case that depends on accuracy and consistent behavior benefits.
Pricing depends on your model scale, cloud usage, security requirements, and operational complexity. Most organizations start with an assessment phase, followed by a tailored plan that fits their growth and budget.
Yes. We offer continuous monitoring, optimization, governance updates, incident support, and performance reviews to keep your models stable as your business evolves.
We work with a mix of enterprise-grade tools for orchestration, evaluation, monitoring, observability, and governance. Tooling is selected based on your stack to ensure smooth integration and long-term scalability.
Build production-ready LLMOps infrastructure that scales with your business
Partner with our experts and get your LLMOps designed to eliminate bottlenecks, reduce costs, and support your expansion from pilot to production.
 100% Secure. Zero Spam.
100% Secure. Zero Spam.By submitting this form you agree with the terms and privacy policy of Softweb Solutions Inc.









