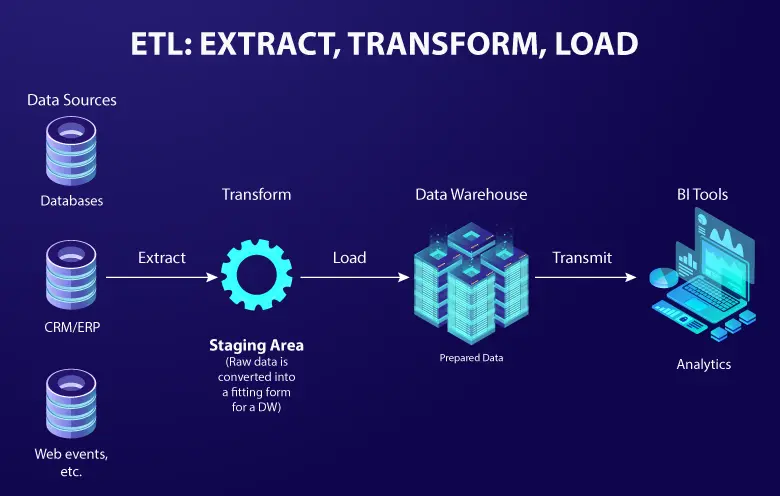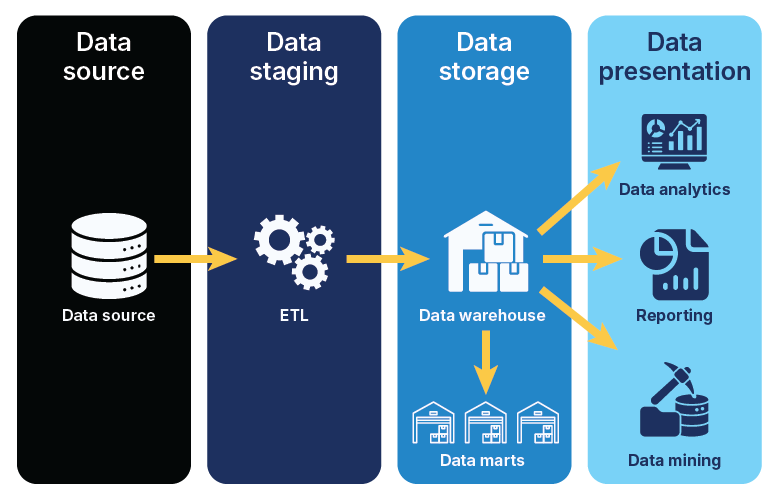
As businesses move toward faster, smarter, and more data-driven decisions, how data is organized, accessed, and delivered becomes just as important as the data itself. That’s where data warehouse architecture plays a critical role. It shapes how the entire organization uses data to grow and innovate.
A well-structured data warehouse enables everything from real-time dashboards to strategic forecasting by ensuring that data from multiple sources flows through a reliable and scalable system. With the growing demand for data warehouse services, understanding how this architecture works is essential to realize long-term value from your data.
In this blog post, we’ll explore the fundamentals of modern data warehouse architecture, what it is, why it matters, and how it supports better use of data. From the main layers and components to how data flows through the system, this post will give you a clear overview of how a well-structured data warehouse can benefit your business.
What is data warehouse architecture?
Data warehouse architecture is the design framework that defines how data is collected, stored, processed, and accessed within a data warehouse system. It organizes data flow across various layers to support efficient reporting, analysis, and decision-making. Bill Inmon, the father of data warehousing has described data warehouse as:
Data warehouse architecture refers to a subject-oriented, integrated, time-variant, and non-volatile collection of data in support of management’s decision-making process.
– Bill Inmon, Scientist and father of data warehouse
Let’s understand the aspects mentioned in this definition in detail:
-
Subject-oriented data
The warehouse data is structured around topics or subjects instead of the applications or the source systems that produce the information. For instance, in a retail or e-commerce business, sales data may come from multiple systems such as POS terminals, online platforms, or CRM tools. All this data can be logically configured and clustered in a data warehouse. Structuring data on subject areas makes it possible to have a single view of the subject instead of various views from different systems.
-
Integrated data
Data from every source system (for example, CRM, ERP, or e-commerce platforms) is consolidated and normalized inside the data warehouse. For example, if one system utilized the name of region as ‘North Dakota’ and another system utilized abbreviation like ‘ND’, an integrated data warehouse would standardize the region name to generate a consistent coding scheme.
-
Time-variant
Warehouse data is kept up to date to enable pattern analysis, AI/ML-driven trend forecasting, and overall reporting. It’s not only a single view of the present moment but a timeline of data that provides businesses with insight into change and evolution over time.
-
Non-volatile
Data stored into the warehouse never gets overwritten or erased, ensuring data is stable and reliable, vital for credible analysis. Data can be added to the warehouse, but data already present in the warehouse cannot change.
The role of data warehouse architecture
The intent behind these fundamental features is to provide a fact-based, decision-making process that can be leveraged by all within the organization, particularly as organizations seek to capitalize on self-service analytics.
Just as a BI architecture is a well-designed system that integrates multiple technologies and BI tools, data warehouse architecture is a deliberate design of data services and subsystems. It unifies different sources of data into one repository to facilitate business intelligence, AI/ML functions, and analysis. The architecture is a collection of logical services forming the core of a data warehouse system that provides a systematic and consistent means of storing, managing, and retrieving huge volumes of data.
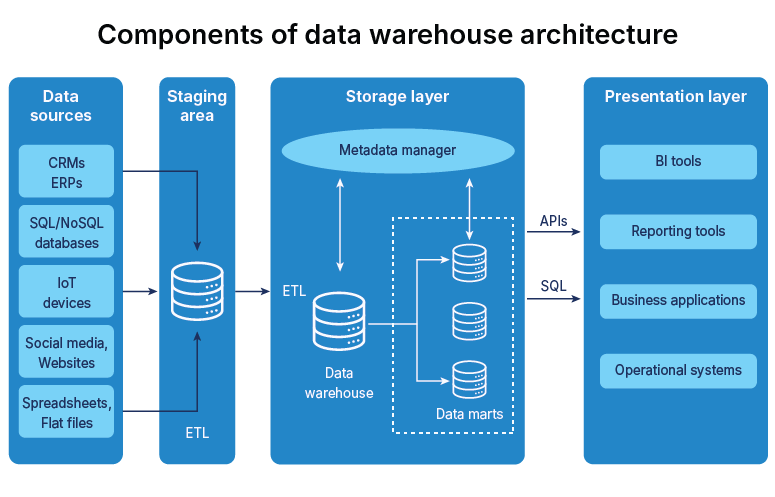
Breaking down the layers of data warehouse architecture
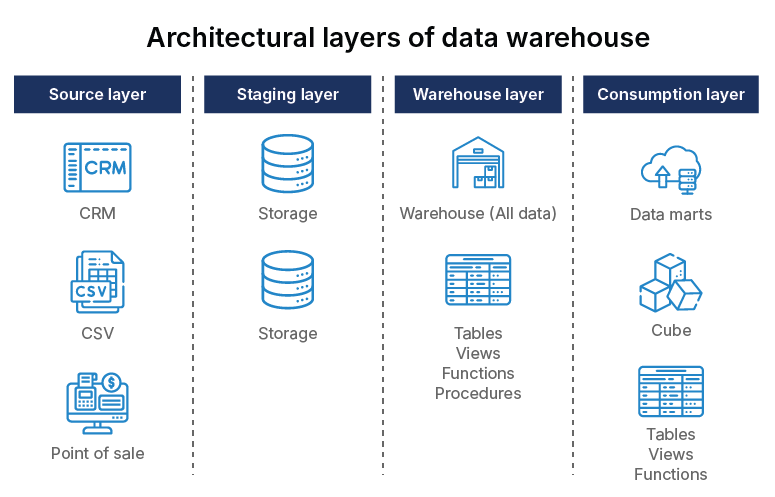
Data warehouses contain several functional layers, each of which has distinct capabilities. The most frequent data warehouse architecture layers include the source, staging, warehouse, and consumption.
-
Source layer
This is the logical layer of every System of Record (SOR) that provides data to the warehouse. For instance, point-of-sale, marketing automation, CRM, and ERP systems. Every source SOR will have a unique data format and might call for a unique data capture technique depending on that data format.
-
Staging layer
It is the staging location from the source SOR for data. One of the best practices for data staging is when staging data is ingested from the SOR without the application of any business logic or transformations. It’s also important not to use staging data for production-level data analysis; data in this stage is not cleansed, standardized, modeled, governed, and validated.
-
Warehouse layer
It is the layer in which all the data is stocked. The warehouse data is now time-variant, integrated, subject-oriented, and non-volatile. In this layer, there are the physical schemas, tables, views, stored procedures, and functions required to access the data modeled in the warehouse.
-
Consumption layer
This layer is also referred to as the analytics layer. It is the layer where you model data for consumption by using analytics tools such as ThoughtSpot. You can also take help from data professionals.
How is data ingested and transformed?
How does data move from the source to the consumption layer? Three fundamental processes are generally required to get data moving, cleaning, and transforming it into warehouses and consumption layers.
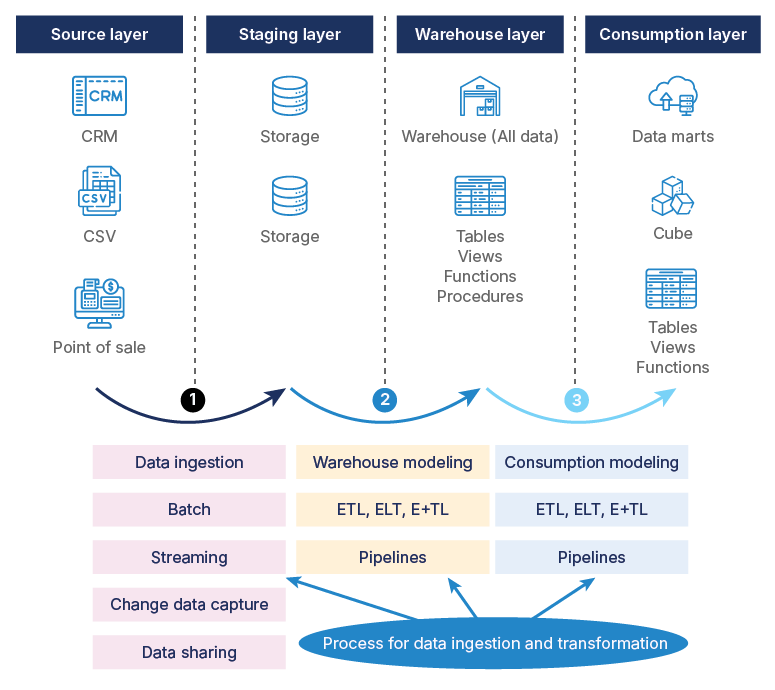
Data is ingested from every system of record. It can also be ingested from files. The most frequent types of ingestion methods can be segregated into various categories of predominant techniques, such as:
-
Batch processing
This is the most used method, even in contemporary data architectures. Batch processing is suitable for most business needs and is tested, proven, simple, and well comprehensible. Yet, it has some limitations, such as data latency, limited scheduling flexibility, intense CPU and disk usage, and difficulties in integrating.
-
Data streaming
This is a technique of processing data in real-time or close to real-time when it is being generated or received. Unlike batch processing, which processes data in bulk at predefined intervals, streaming continuously ingests, processes, and analyzes data, with the capability to facilitate instant insights and action based on the stream of incoming data.
-
Change Data Capture (CDC)
CDC utilizes the database transaction logs of the SOR to pick up any data that has been created, updated, or deleted. This strategy guarantees that only the changed data is ingested. CDC process is normally run periodically, for example, every hour or every day. It’s excellent for synchronizing Operational Data Stores (ODS) and staging data for transactional systems of record.
-
Data sharing
In conventional data ingestion processes, data is copied or relocated. But data sharing by cloud data providers such as Snowflake or Databricks does not involve data duplication. This process offers real-time data sharing and is commonly utilized by companies adopting Data Mesh, a decentralized data architecture that organizes data by a specific business domain.
What are the key components of modern data warehouse architecture
Each data warehouse architecture is made up of architectural layers, data ingestion and transformation processes. Those processes and layers are also based on common elements of the data architecture.
-
Data lakehouse architecture
The data lakehouse is the integrated platform for storing and processing all forms of data. It blends the data lake’s flexibility with management capabilities of traditional data warehouses. The data lakehouse manages both structured and unstructured data, accommodating anything from SQL analytics to machine learning workloads, with features that maintain data quality and performance.
-
Data integration tools
Two primary methods of data management are supported by data integration tools: direct integration and data virtualization. Direct integration tools bring data into the central database and convert it into a standard format for analysis through techniques such as ETL (Extract, Transform, Load), ELT (Extract, Load, Transform) and real-time and bulk-load processing. Data virtualization provides an interface to query data where it is located through federation by giving an aggregated view across dispersed data sources without moving data. These methods can be combined, assisted by automation, orchestration, and data quality and enrichment.
-
Metadata
Metadata is data about data, which is used for data management and governance. Metadata gives information and background about the data including sources, transformations, structure, relationships and use. Technical metadata specifies schemas, data types and lineage, whereas business metadata explains data in nontechnical terms.
-
Data access tools
Data access tools enable users to query, analyze and visualize data residing in the data warehouse and fill the gaps between raw data and decision makers. Data access tools consist of reporting software, BI platforms, OLAP tools, data mining tools, application development tools and APIs that provide access to data for both nontechnical and technical users.
-
Embedded AI and ML capabilities
Contemporary data warehouses also feature integrated AI and ML functionalities that facilitate automatic processing of data, pattern recognition, anomaly detection and predictive analytics. All this is embedded within the warehouse environment, hence eliminates the need for an independent AI/ML software.
-
Interactive dashboards
Visual analytics dashboards deliver real-time access to data insights through interactive graphs, charts and reports. The self-service interfaces enable nontechnical as well as technical users to discover data, build visualizations, and derive insights without writing difficult queries.
-
Governance framework
An exhaustive governance platform handles data access controls, security guidelines, compliance, and data quality norms. It comprises tools for data lineage tracking, audit classification, privacy protection, and regulatory compliance management for the entire data warehouse infrastructure.
Build a stronger future with the right data foundation
A well-planned data warehouse is about making your data usable, reliable, and ready to support every business decision you make. As your business grows, so does the complexity of your data. Without the right structure, it becomes harder to manage, analyze, and trust that data.
This is where data warehouse architecture can make a real difference. It helps you design, implement, and maintain a system that keeps your data organized, accessible, and ready for insight. Embracing the right architecture today means building a smarter, more future-ready business tomorrow. To know more about the best data warehouse architecture and how implementing it will help grow your business, talk to our data experts.