
When traditional databases were created, they held their place in multiple applications, and even scaled as requirements grew. Back then, smart phones and the Internet of Things were years away and big companies did the heavy lifting with the data generated at that time. As the use of Internet across the globe increased exponentially, the sheer number of people trying to access data at the same time brought the need for bigger servers and mainframes, which turned out expensive from setup to maintenance.
This boom also led to the quest for analysis, which brought a further need to divide data into operational and analytical, paving the way for data warehouses. Eventually, distributed computing made its mark in database management, which, powered by the cloud, greatly reduces costs, saves time and significantly boosts processing power.
The one that started it all – Hadoop
To work around an existing problem, an alternative is designed. Every time a big company faces a problem, there comes a solution, which may turn out beneficial for the industry. When Yahoo wanted to build open-source technologies in 2006, they employed Doug Cutting, who was working on an open-source search engine by the name of Nutch. They took the processing and storage part of Nutch to create Hadoop, which synonymized itself with big data and also spawned numerous startups and commercial distributors.
But sometimes, the result of a workaround, though it works, creates problems of its own. In other words, Hadoop has been known to have drawbacks. The good thing is that they do get countered by some company that develops another workaround, which may be released publicly.
It is possible to carry out real-time processing in Hadoop with technologies like Apache Kafka, Apache Spark, and Apache Kudu. Apache Hive gives Hadoop an SQL-like syntax, making it suitable to analyze large, relatively static data sets. Eventually, Hadoop might become an underlying technology which people might not even be aware of. Its prevalence will not go down, just the hoopla surrounding it. It has been known to be referred to as the SQL-unfriendly stuffed elephant, because for real-time processing, options that work on top of Hadoop are a better choice.
Many companies have reportedly shut down their Hadoop distributions, or have moved to other established ones like Cloudera, Hortonworks, and MapR. This may seem like Hadoop is in trouble, but in reality it is just being replaced by itself, albeit on a different platform, since it is basically a framework.
Going for the Apache Hadoop download might not be the best option for many users as it can be an overwhelming experience. Using the free route may not always be the best choice, unless you know what you are doing. This is because businesses need trained and experienced developers who are familiar with the Hadoop ecosystem. This is where the role of a IT consultant becomes important.
Enter NewSQL
NewSQL was born due to the organizational need for faster processing of data in real-time as batch processing was just not cutting it. When the batches were being processed, new data kept streaming in. The backlog became bigger with each passing instance, resulting in inefficiencies.
Based on the relational model, NewSQL starts as an SQL database but offers horizontal scalability and can handle big data, like its NoSQL counterpart. The advantage here is that NewSQL database systems guarantee ACID transactions, which are important for online transaction processing (OLTP).
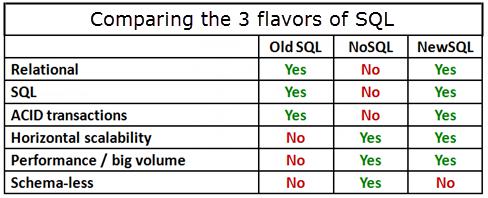
As seen in the table above, NewSQL is not schema-less, which is the only thing preventing it from conquering the table. Proponents of NoSQL may argue that schema won’t help all that much if the database itself does not scale well, but schema is useful for data validation. It is the simplest way to ensure that the right data type is in its designated column. It also helps in reverse indexing, which is important for high volume transaction processing systems.
These developments seem to be promising, and we may see a rise in NewSQL adoption. The only downside here is that NewSQL suffers from being the new entrant. Users tend to go the traditional RDBMS way since they have been dominant and established.
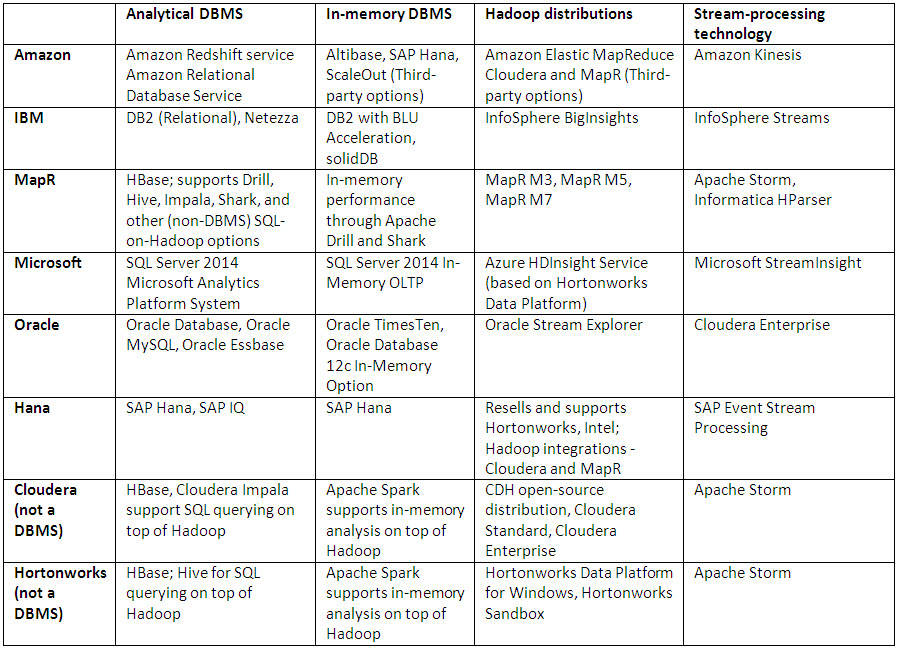
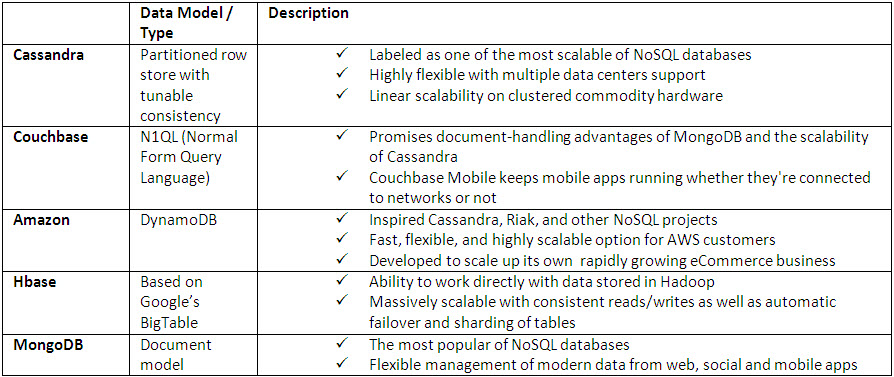
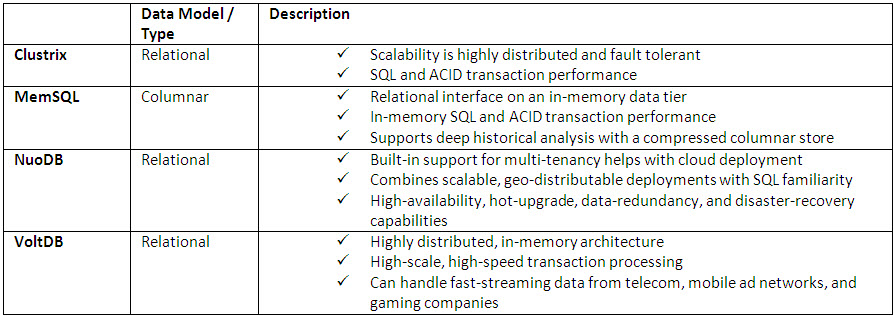
The tables below list few of the popular SQL, NoSQL, and NewSQL databases.
SQL
NoSQL
NewSQL
So which is it? Old, No, or New?
Earlier, the choices were either proprietary or open-source, and the needs were limited. The establishment of NoSQL and the emergence of NewSQL have opened up the entire database market. The answer still remains the same, that there cannot be one winner here. It all depends on the business and its requirements. Existing infrastructures, cloud deployments and software environments need to be carefully analyzed before adopting a new database or migrating to another one. On top of that, you have to be aware of the support that they provide.
What is clear is that the database platter is offering tons of SQL, NoSQL, and NewSQL options. To avoid database selection, implementation or maintenance headaches, contact us and leave your database worries to the masters.






